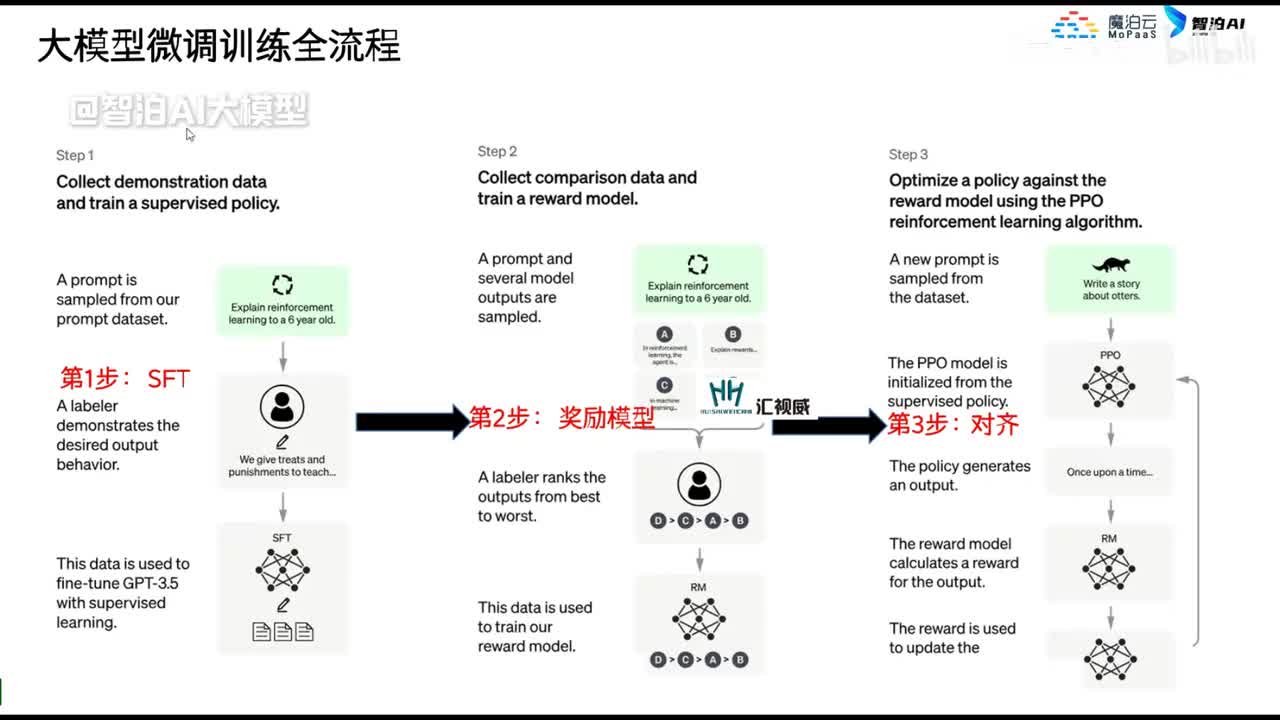
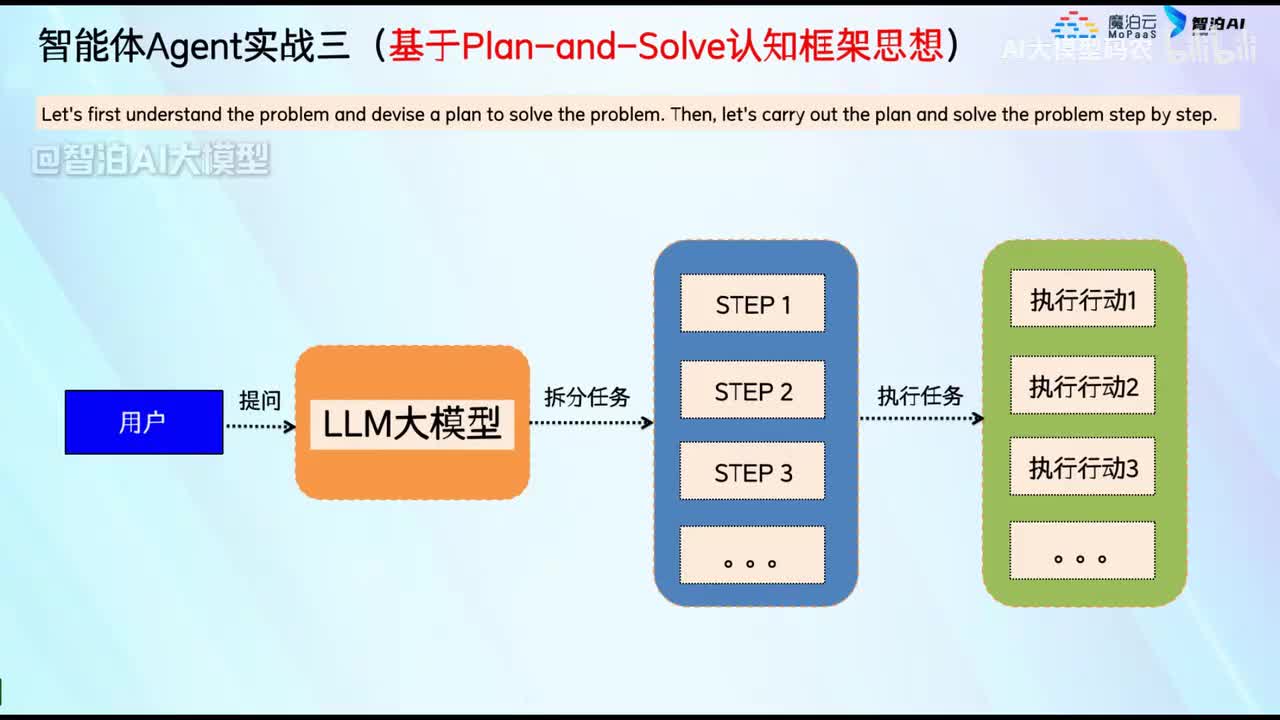
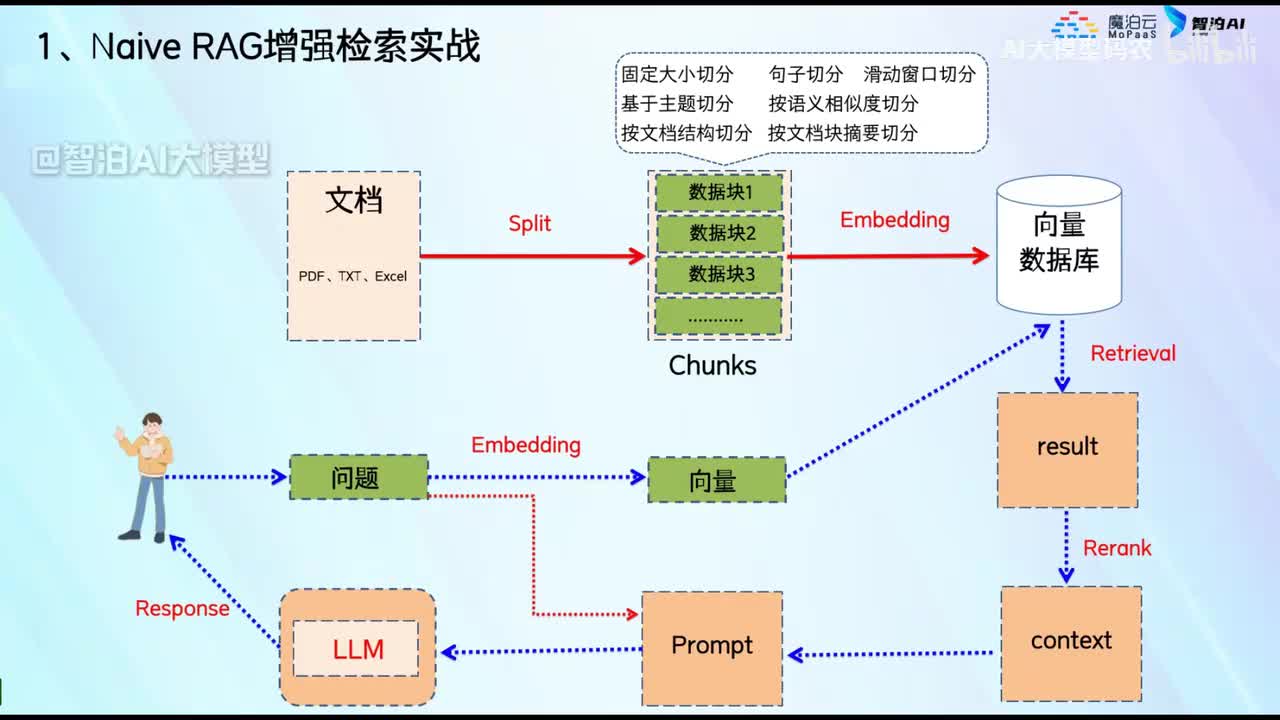
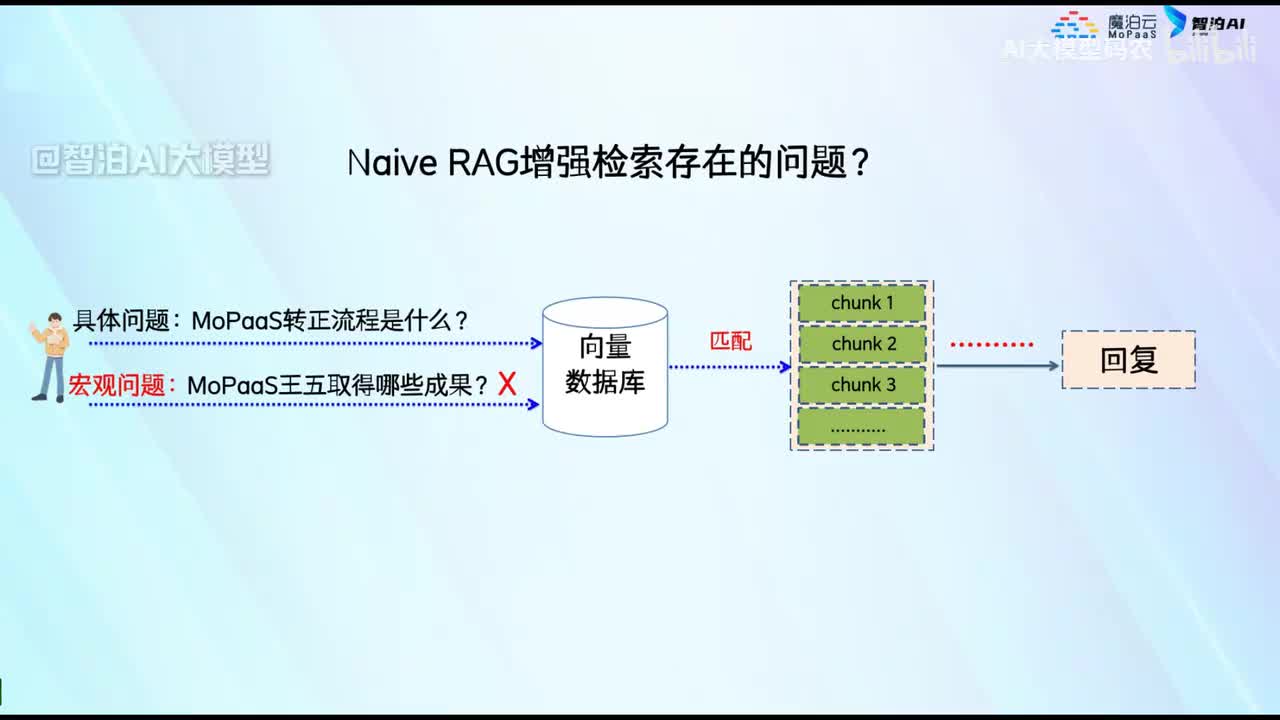
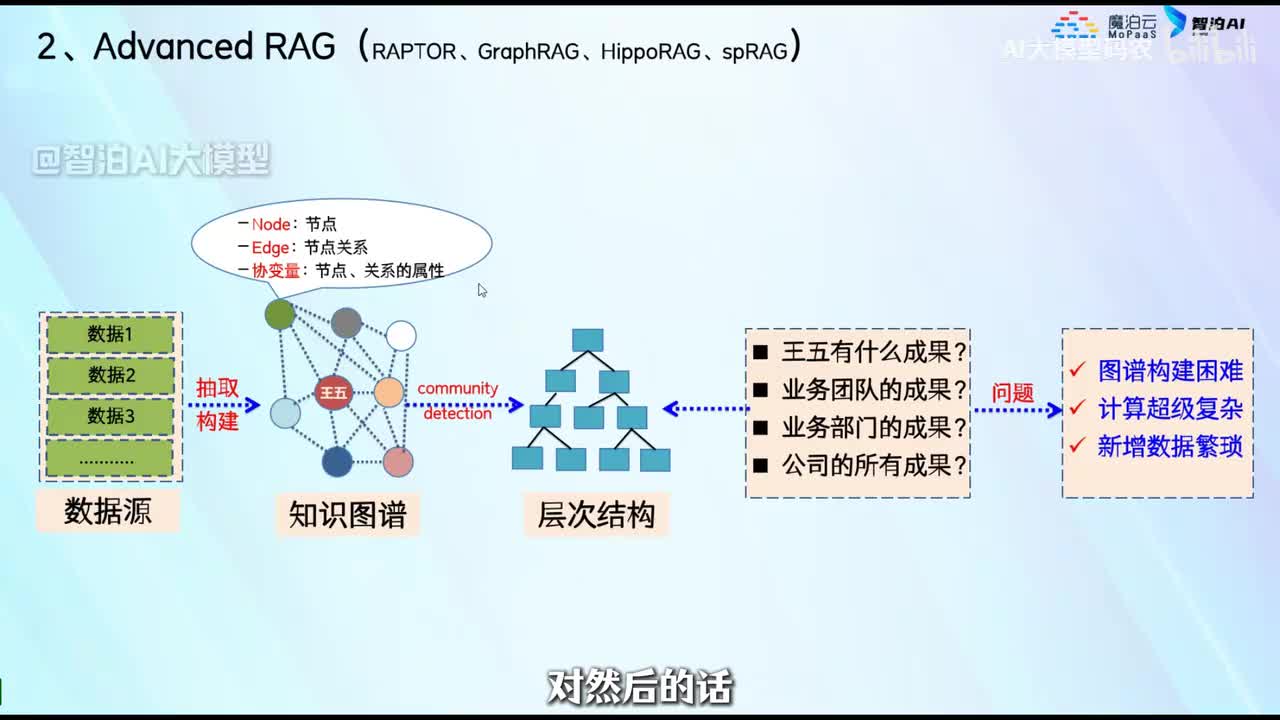
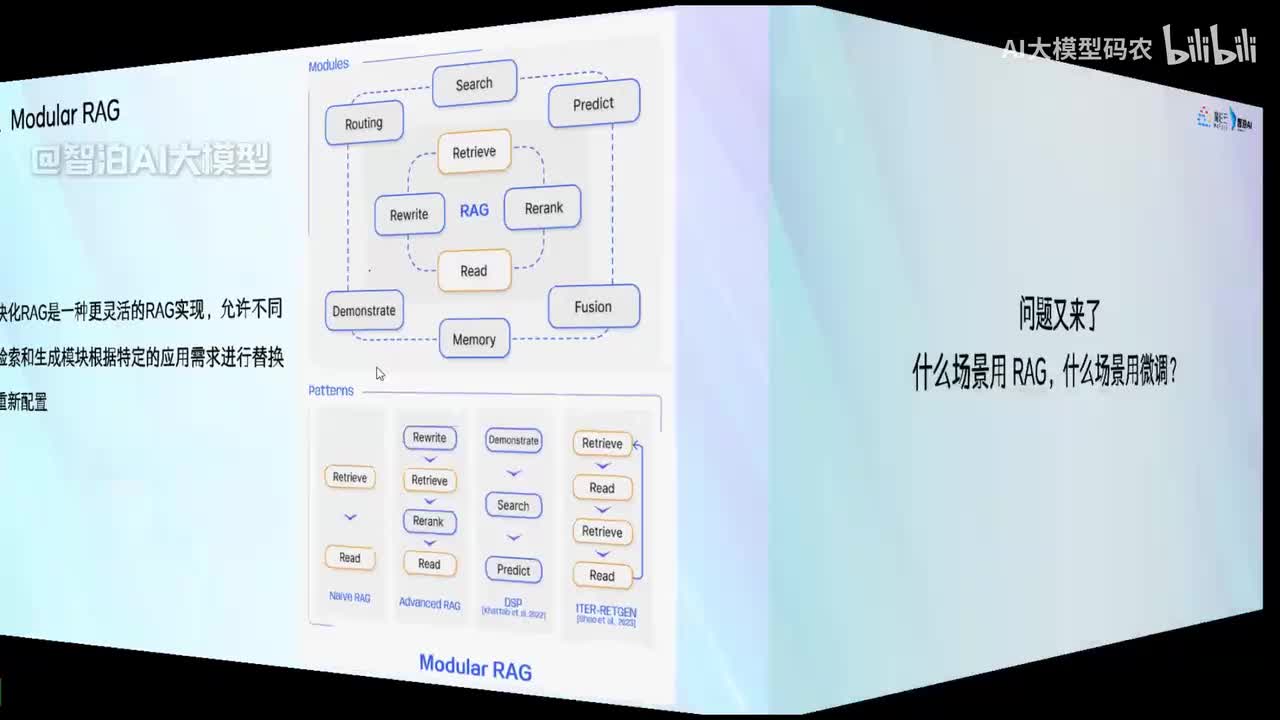
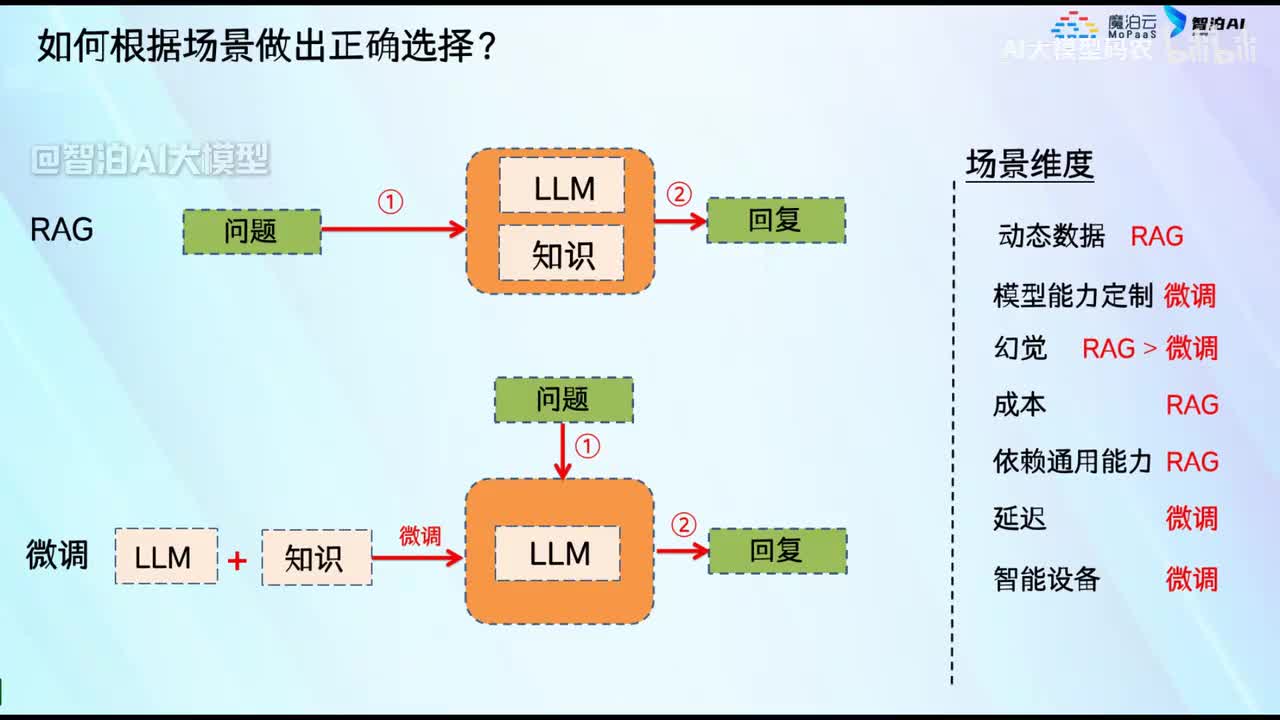
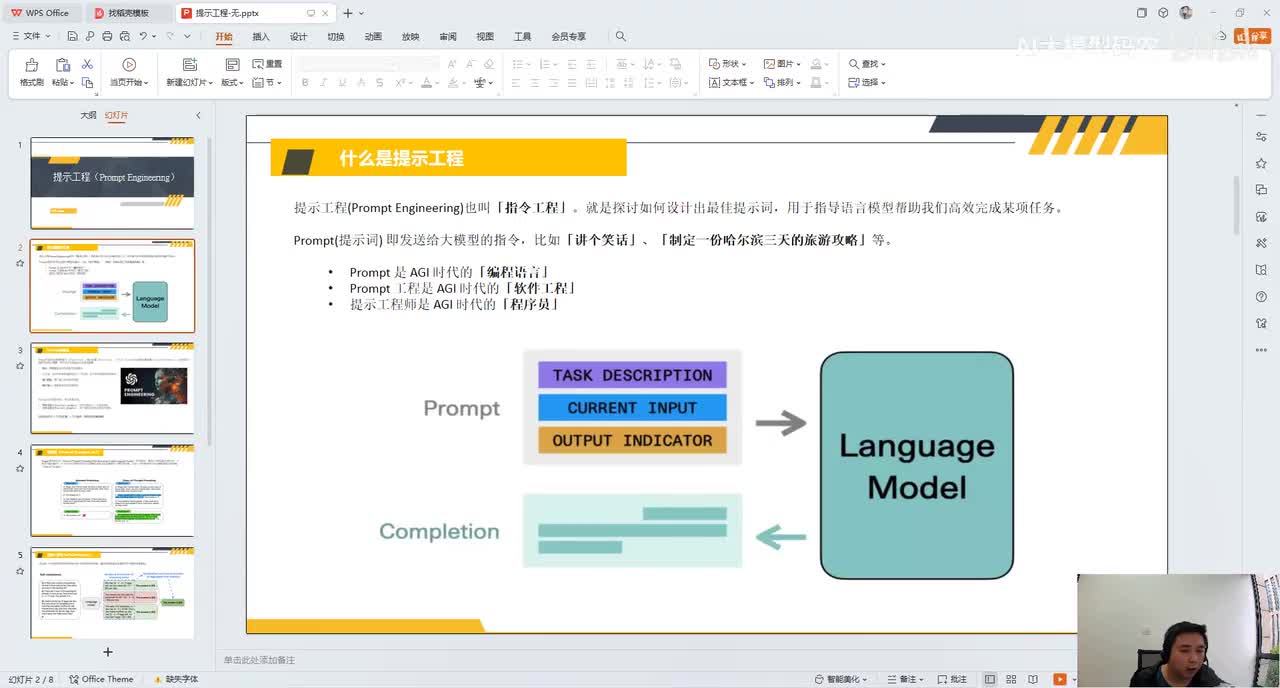
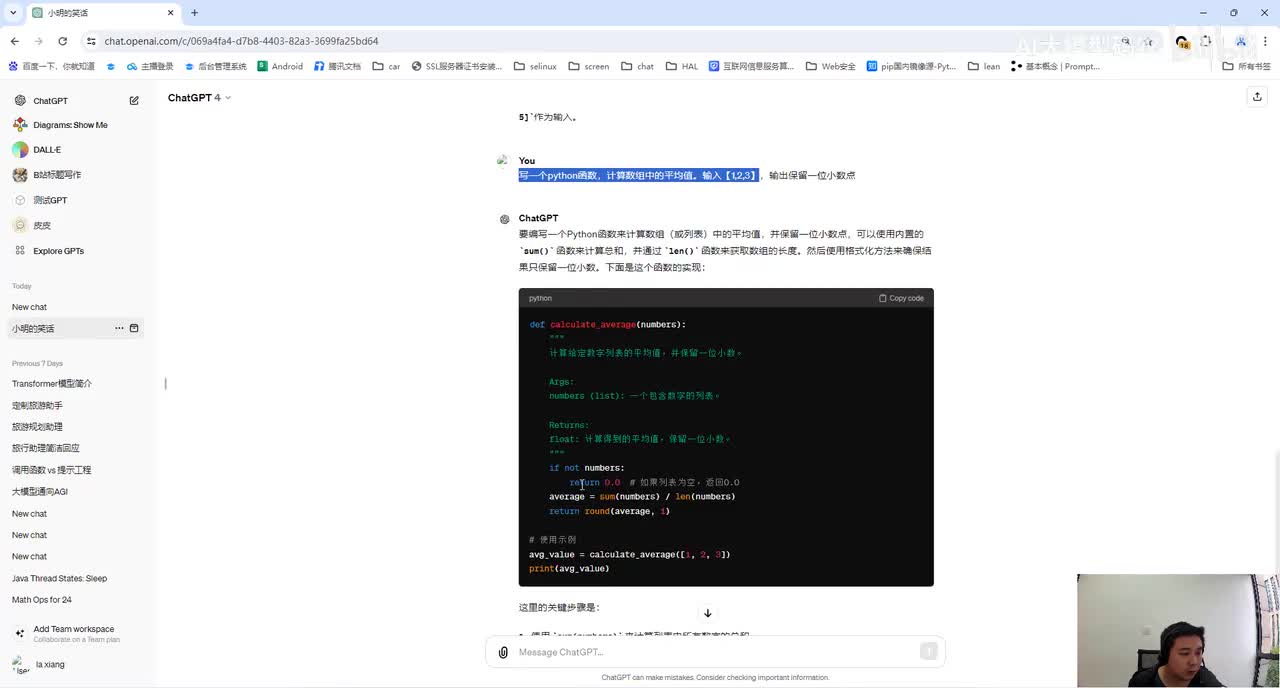
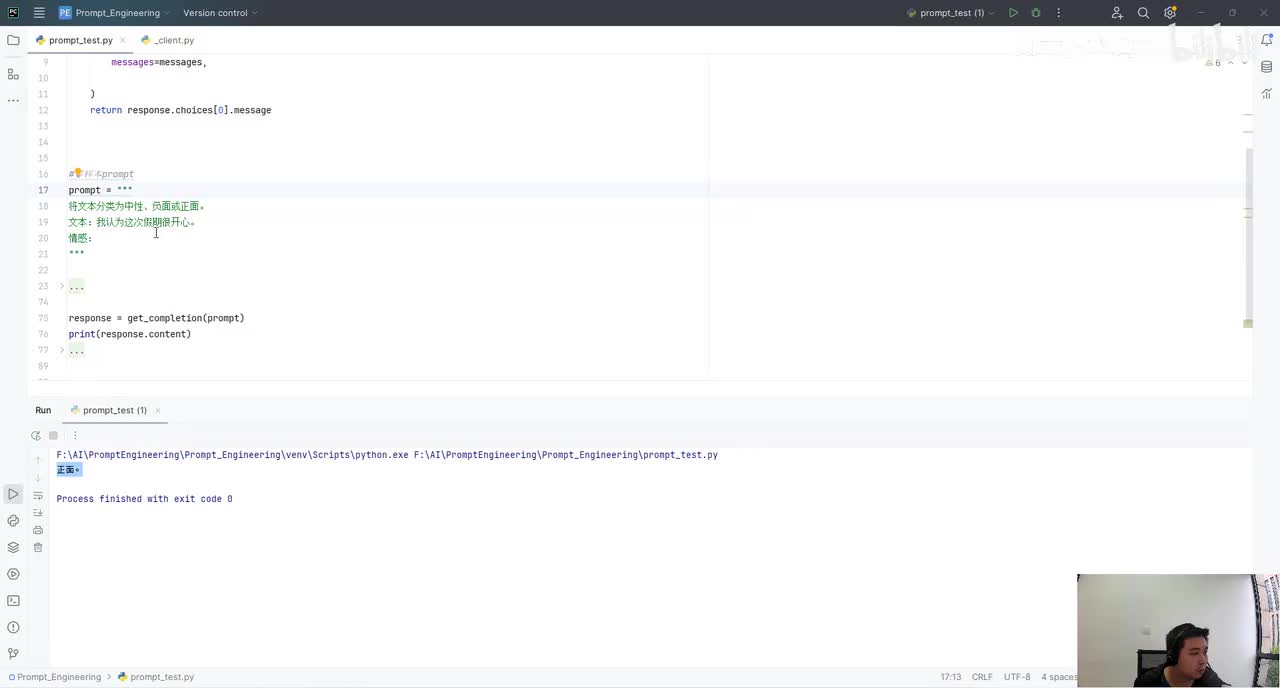
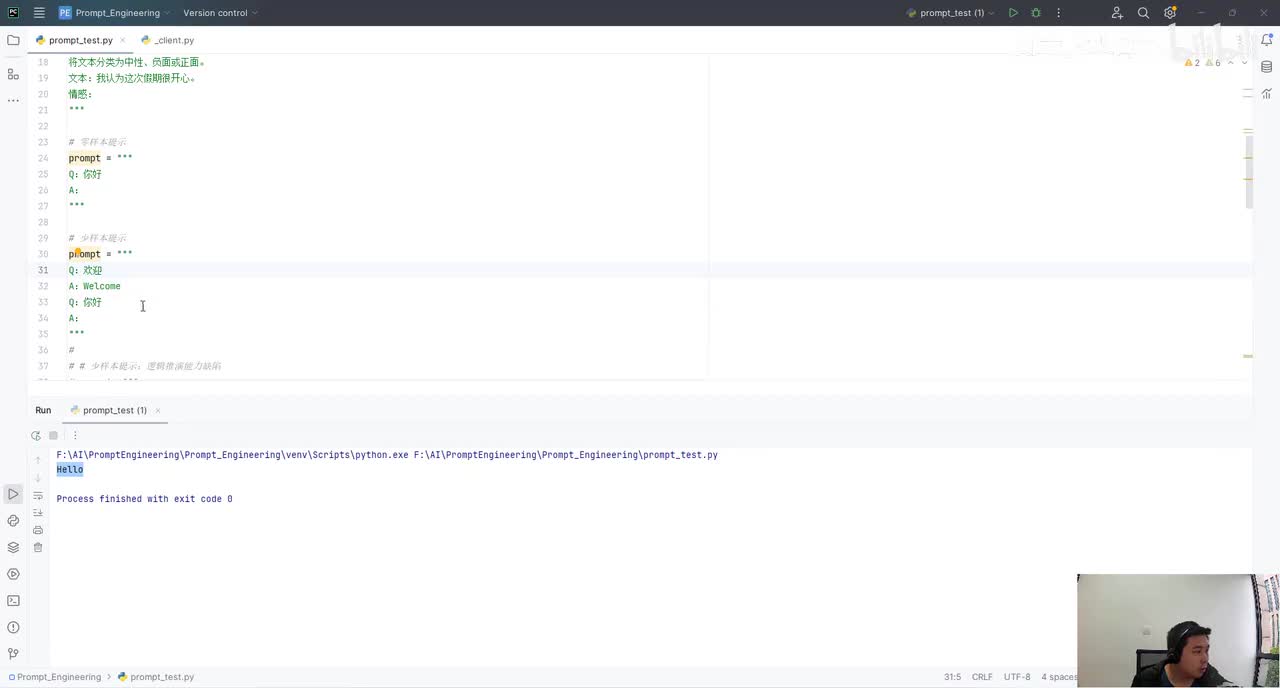
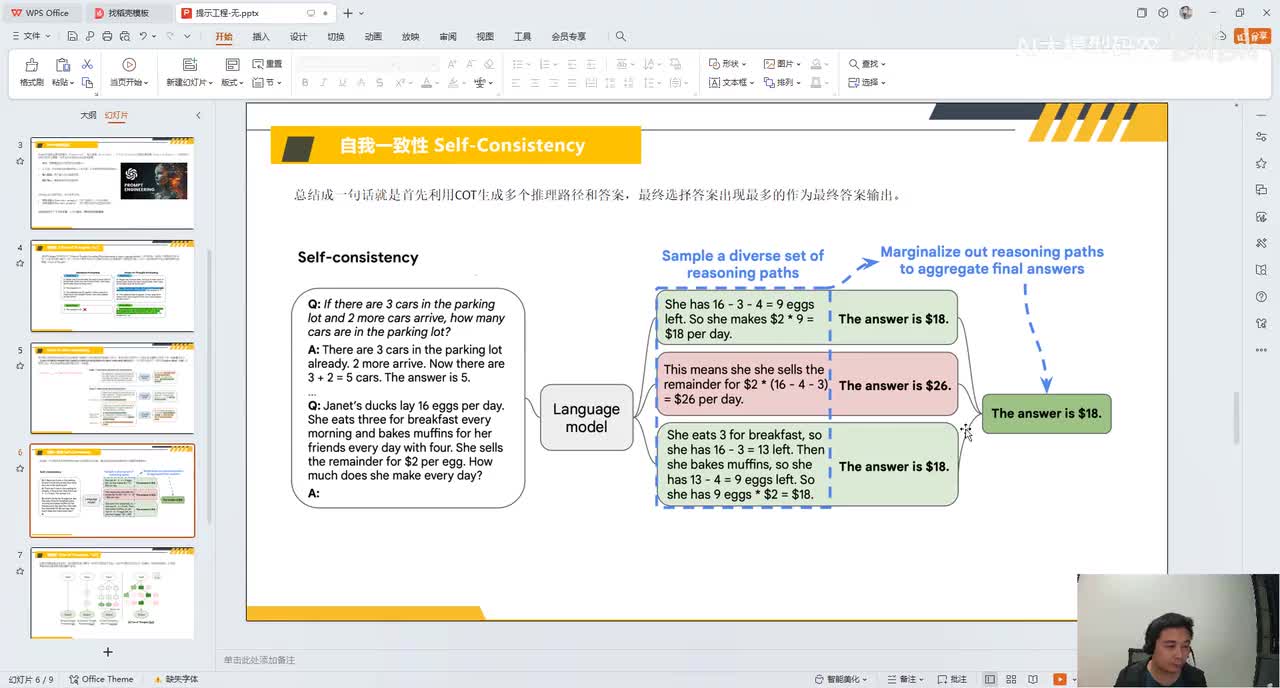
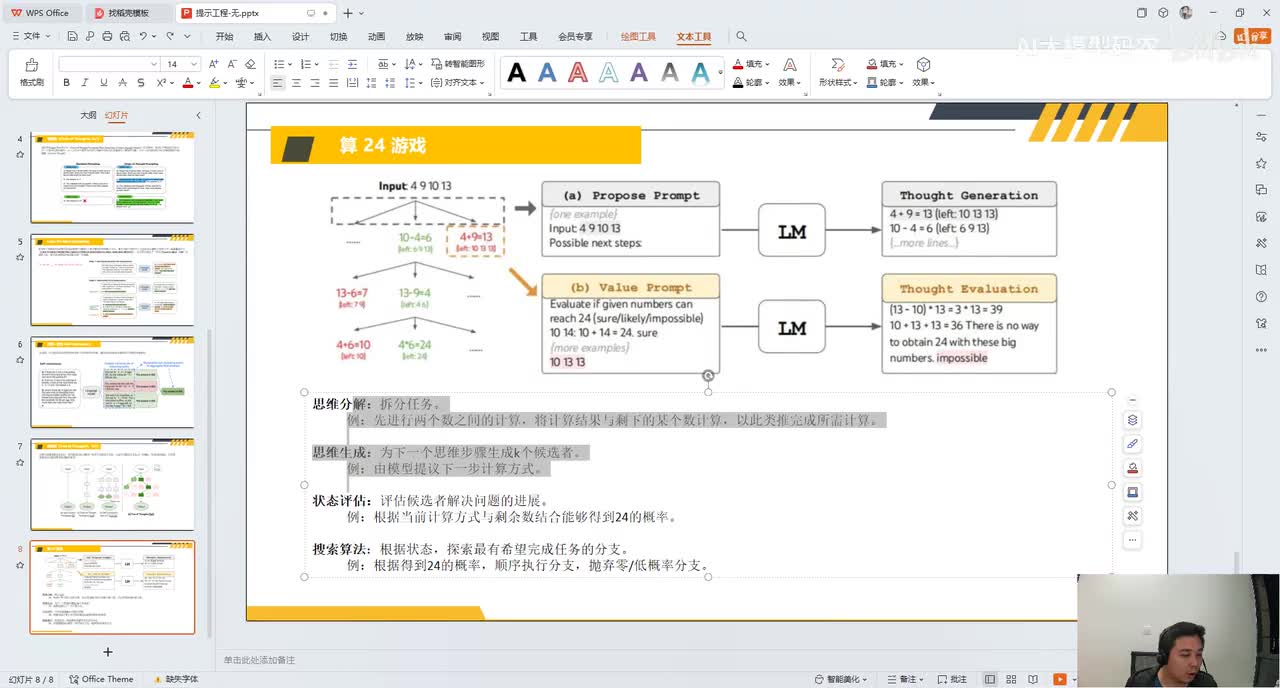
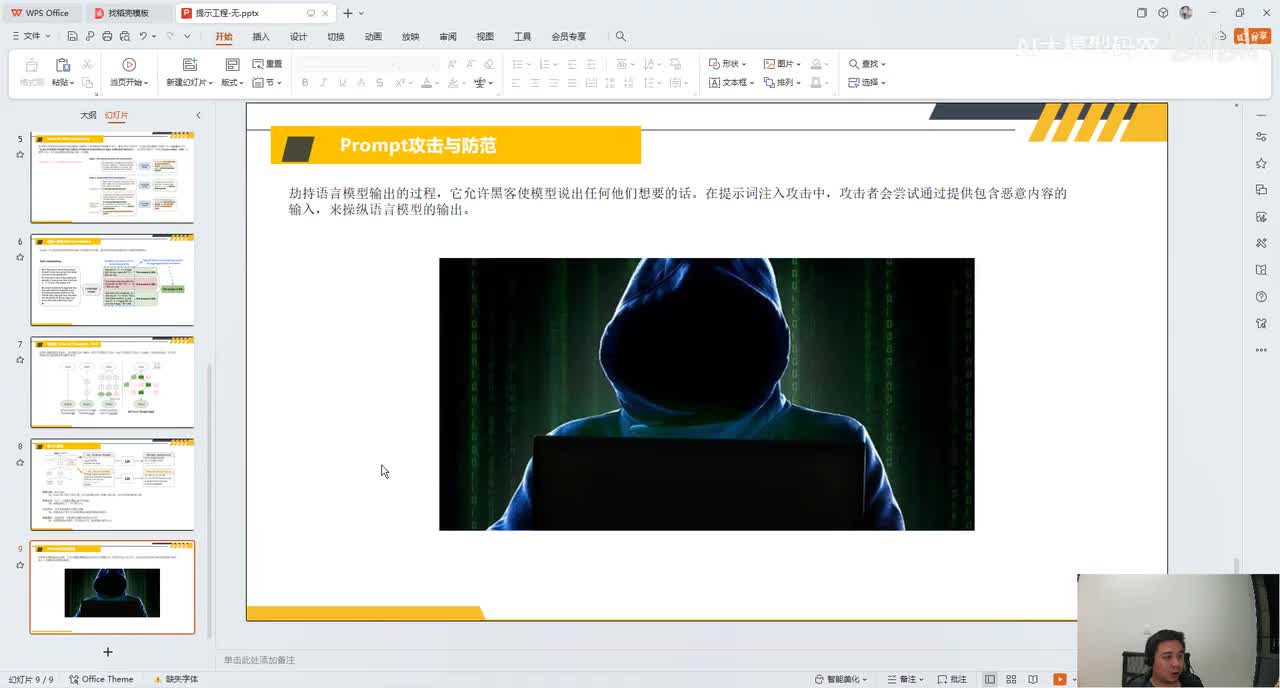
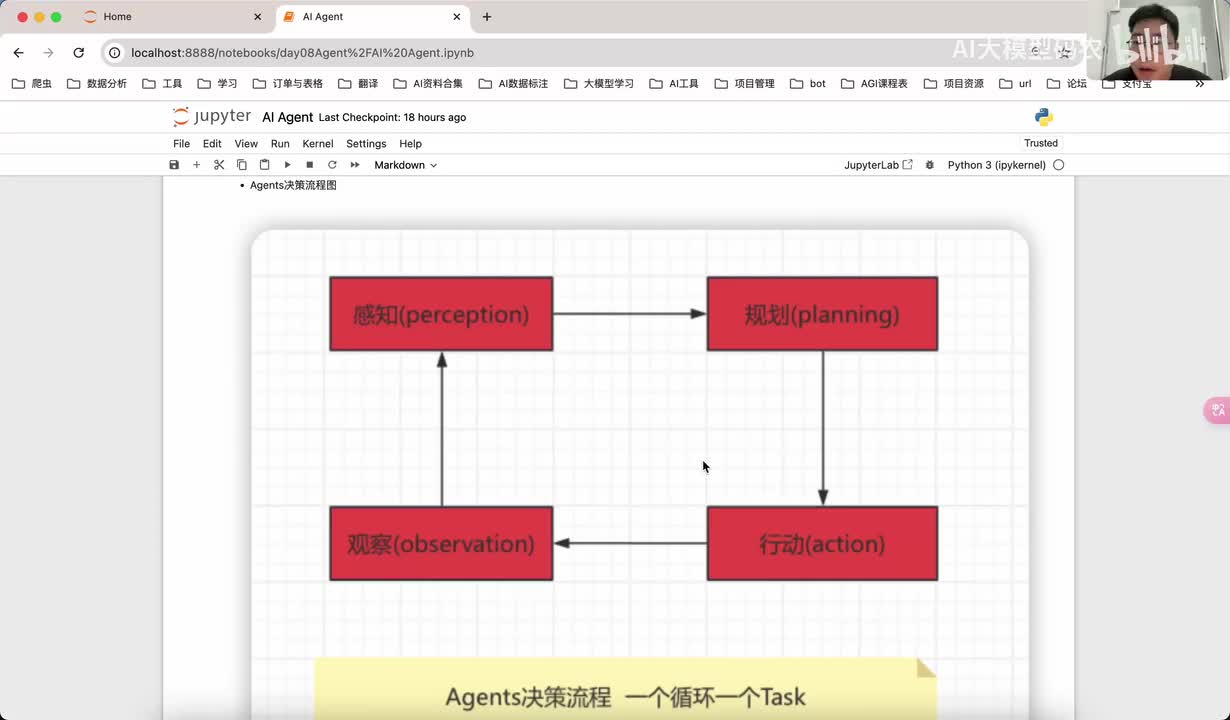
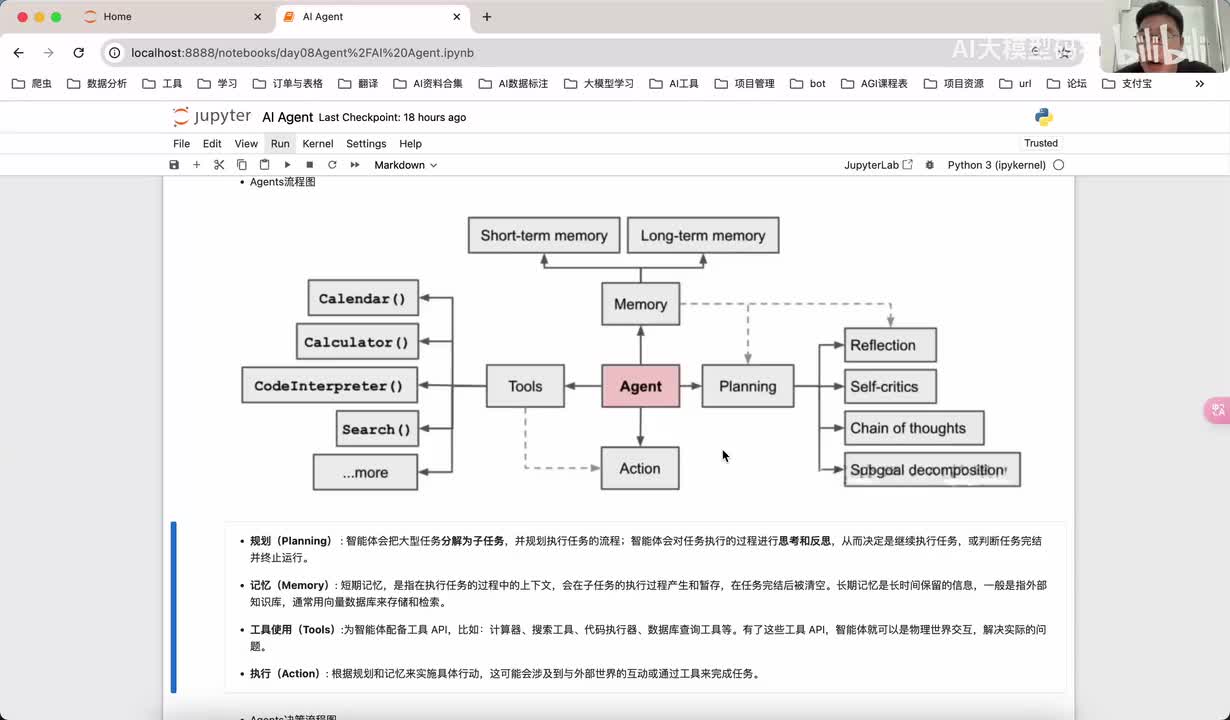
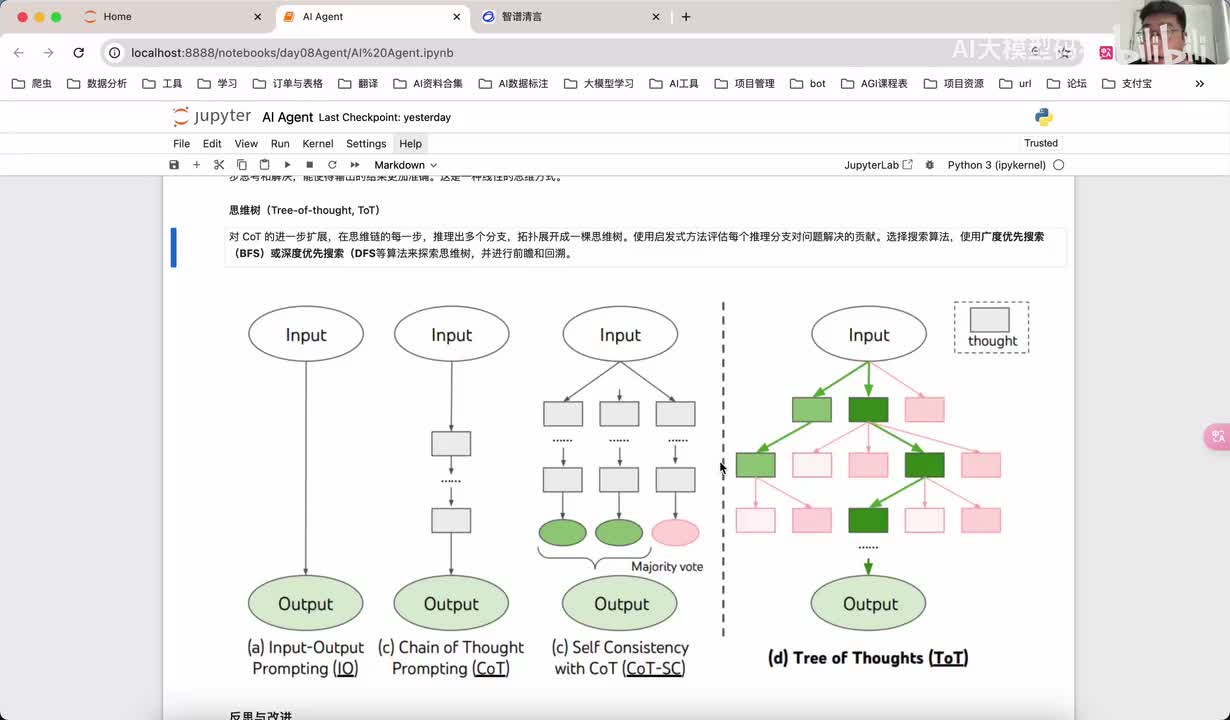
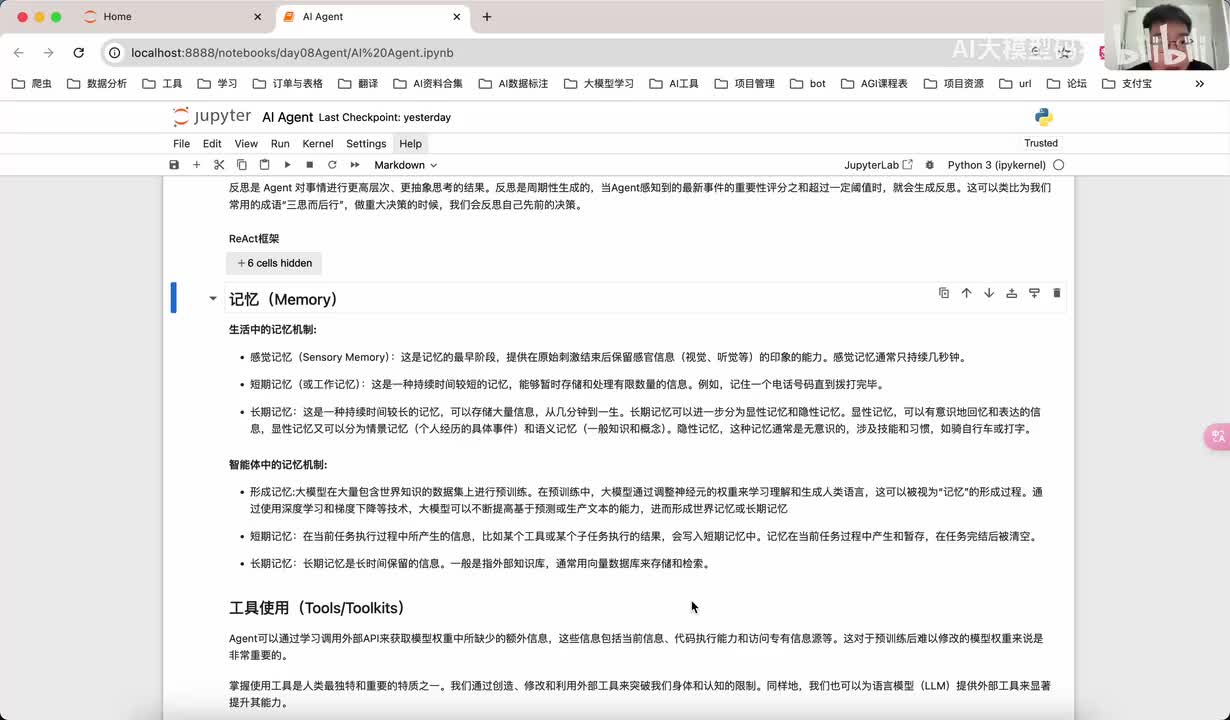
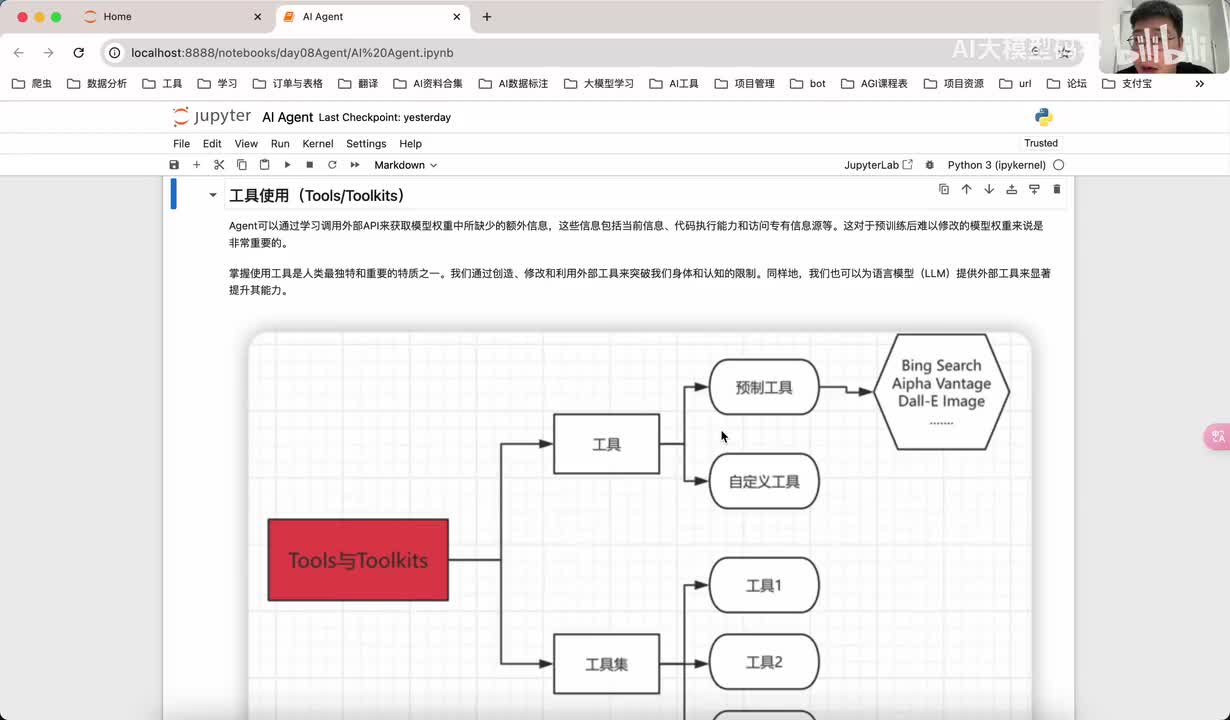
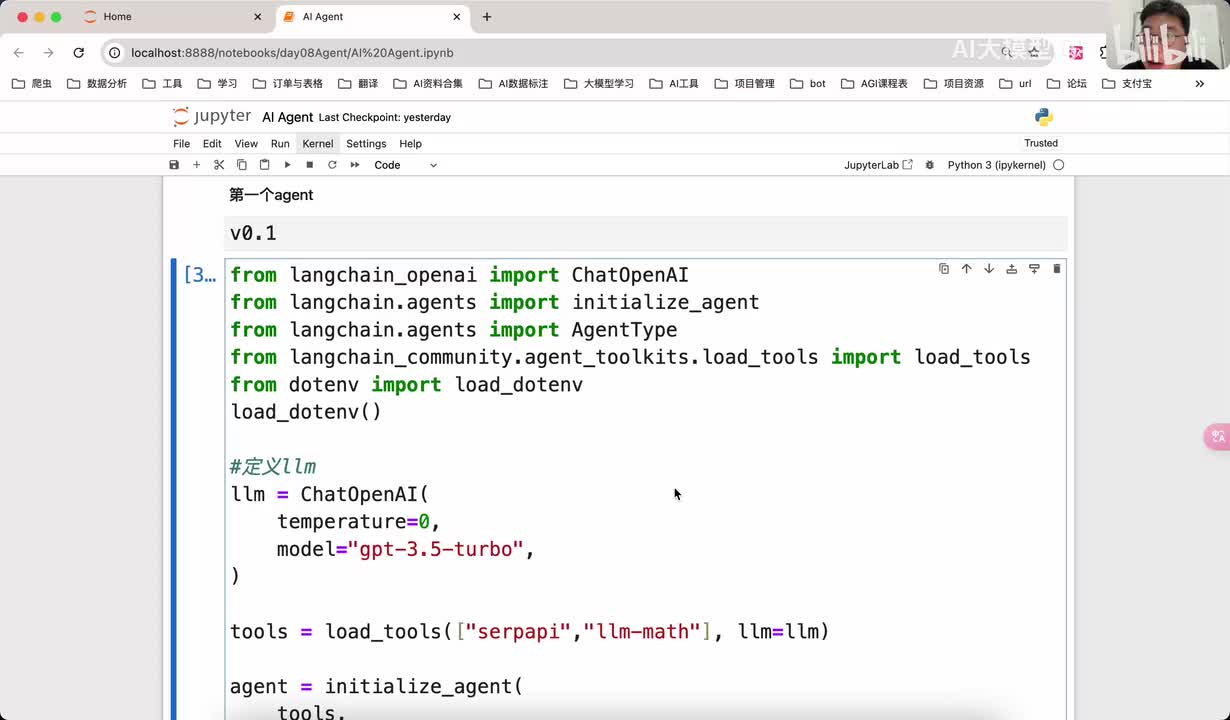
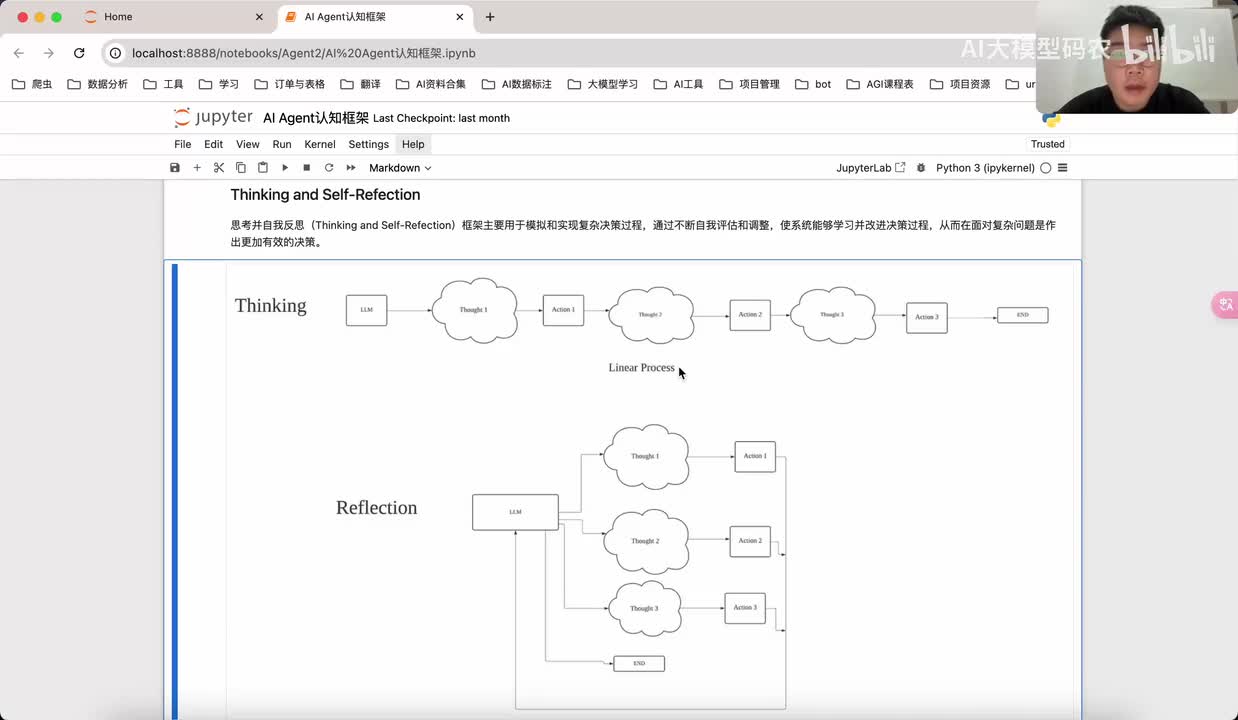
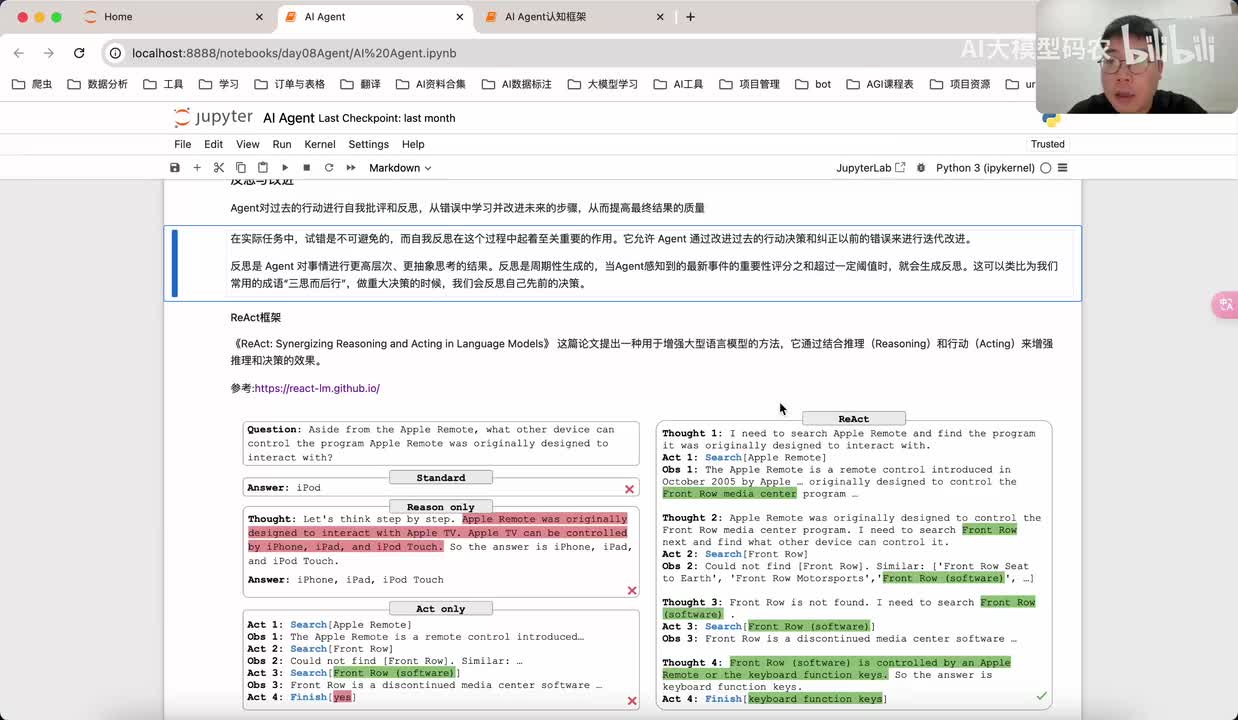
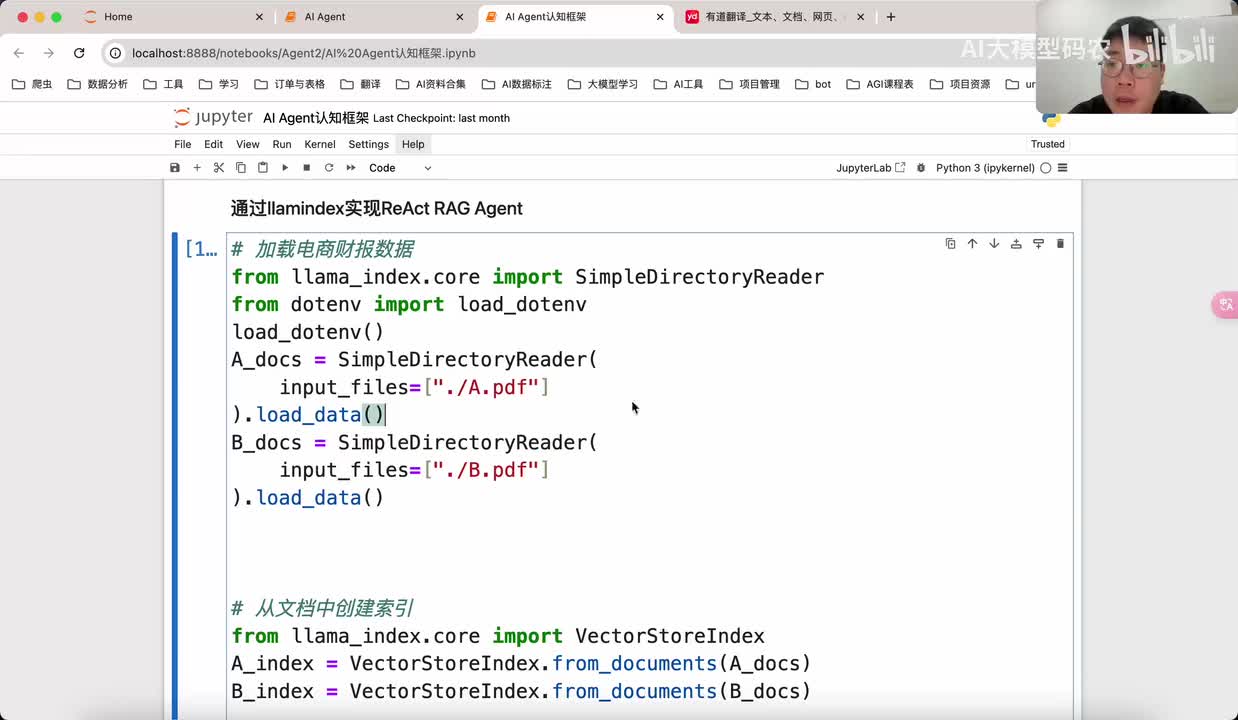
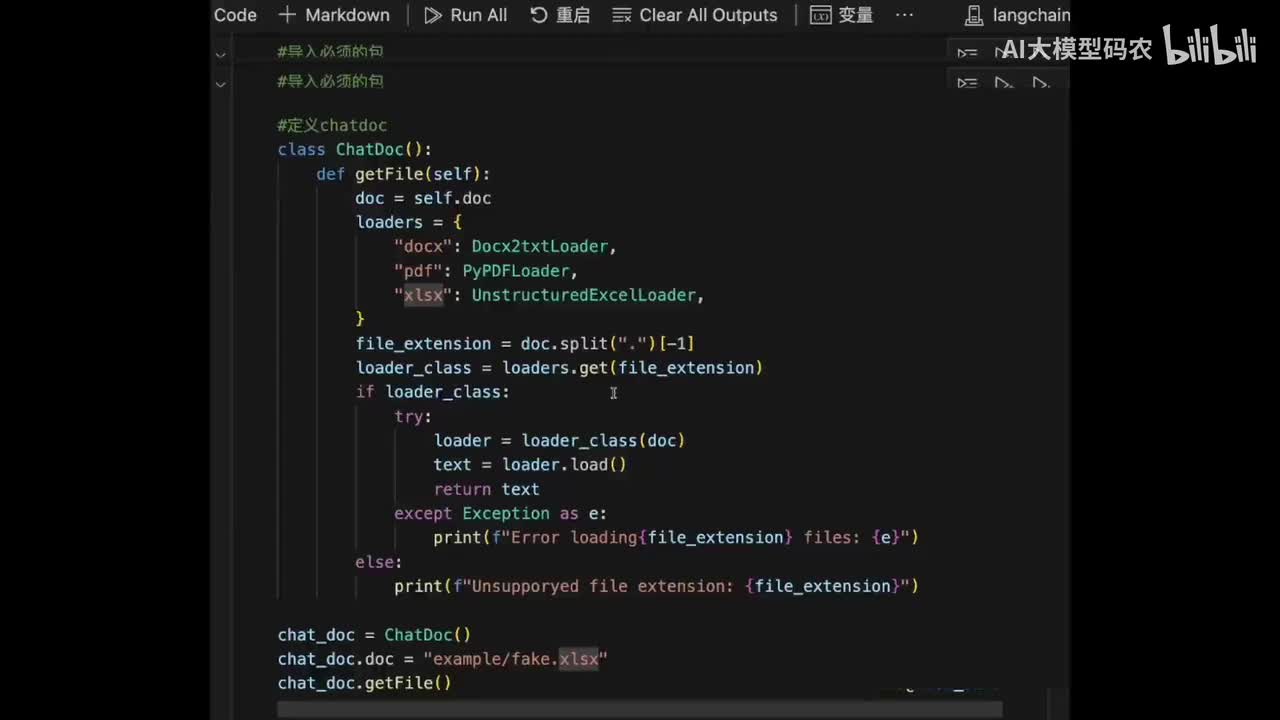
视频选集 00. 最近火爆的Gemini提示词工程指南 01. 1小时窥探私有化大模型底层技术 02. 大模型微调训练全流程讲解 03. 智能体Agent实战 04. 大模型幻觉 05. Naive RAG增强检索实战 06. NaiveRAG增强检索存在的问题? 07. Advanced RAG 08. Modular RAG 09. 什么场景用RAG,什么场景用微调? 10. 微调与RAG的案例场景 11. IT行业转岗分析 12. 什么是提示工程 13. Prompt的组成元素 14. OpenAI调用 15. 少样本提示 16. 思维链COT 17. Ltm提示方法 18. 思维树TOT 19. 思维树算24数代码落地 20. Prompt的攻击与防护 21. LangChain系统教程1 - 基本架构和环境配置 22. LangChain系统教程2 - 模型IO 23. LangChain系统教程3 - 检索外部数据 24. Agent概念、组成与决策 25. Agent决策应用场景分析 26. Agent规划子任务拆解_COT与TOT_ 27. 思维树24点拓展与react框架 28. Agent记忆(memory) 29. Agent工具使用介绍 30. Agent代码初体验、工具使用、记忆添加 31. Agent认知框架之Plan-and-Execute 32. self-Ask 33. Thinking and Self-Refection 34. ReAct框架案例实现 35. ReAct RAG Agent 36. Agent+RAG个性化定制数字人项目 37. Agent+RAG个性化定制数字人项目2 38. 什么是RAG? 38. RAG的原理 40. RAG应用案例:阿里云AI助理 41. 动手实验1-创建RAG应用 42. 动手实验2-连接钉钉机器人 43. 提升索引准确率 44. 让问题更好理解 45. 改造信息抽取途径 46. loader:让大模型具备实时学习的能力 47. 文档转换实战:文档切割 48. 文档转换实战:总结精炼和翻译 49. Lost in the middle 长上下文精度处理问题 50. 文本向量化实现方式 51. 与AI共舞的向量数据库 52. Chatdoc 又一个智能文档助手(上) 53. Chatdoc 又一个智能文档助手(下) 54. ChatDoc 几种检索优化的方式 55. ChatDoc 与文件聊天交互 56. 本章小结 57. Standford Alpaca 的介绍 58. self - instruct 的代码解读 59. Alpaca 7B的微调过程 60. self - instruct 代码的详细过程 61. Standford Alpaca 微调代码拆解:微调方式 62. Standford Alpaca 微调代码拆解:train . 63. 垂直领域微调的方式 64. Huggingface的Transformer库 65. Alpaca-LoRA-消费级显卡的Lora微调 66. DeepSpeed-Chat的LoRA源码解读 67. 基于Huggingface的Peft框架的Lora微调方式 68. Alpaca所用的self-instruct的影响力 69. Alpaca-LoRA微调过程 70. LLaMA2相比LLaMA1的改进 71. LLaMA2的分组查询注意力(GQA) 72. LLaMA2-Chat中的RLHF:三阶段训练方式 73. ChatGLM-6B的数据处理及文件准备 74. ChatGLM-6B的部署及微调过程 75. 微调方法—Freeze方法 76. 微调方法—prefix-tuning与prompt tuning方 77. 微调方法—P-tuning V1方法 78. 微调方法—P-tuning V2方法 79. 微调方法—Lora方法 80. 微调方法—QLora方法 81. LLM微调经验分享 82. 评估基准C - EVAL及ChatGLM2 - 6B的改进 83. ChatGLM2 - 6B的部署推理过程 84. 基于P - Tuning V2微调ChatGLM2 - 6B 85. 通义千问—Qwen - 7B模型的特点 86. Qwen-7B-Chat模型的微调数据构成 87. Qwen - 7B - Chat 模型的ReAct Prom 88. ReAct代码示例