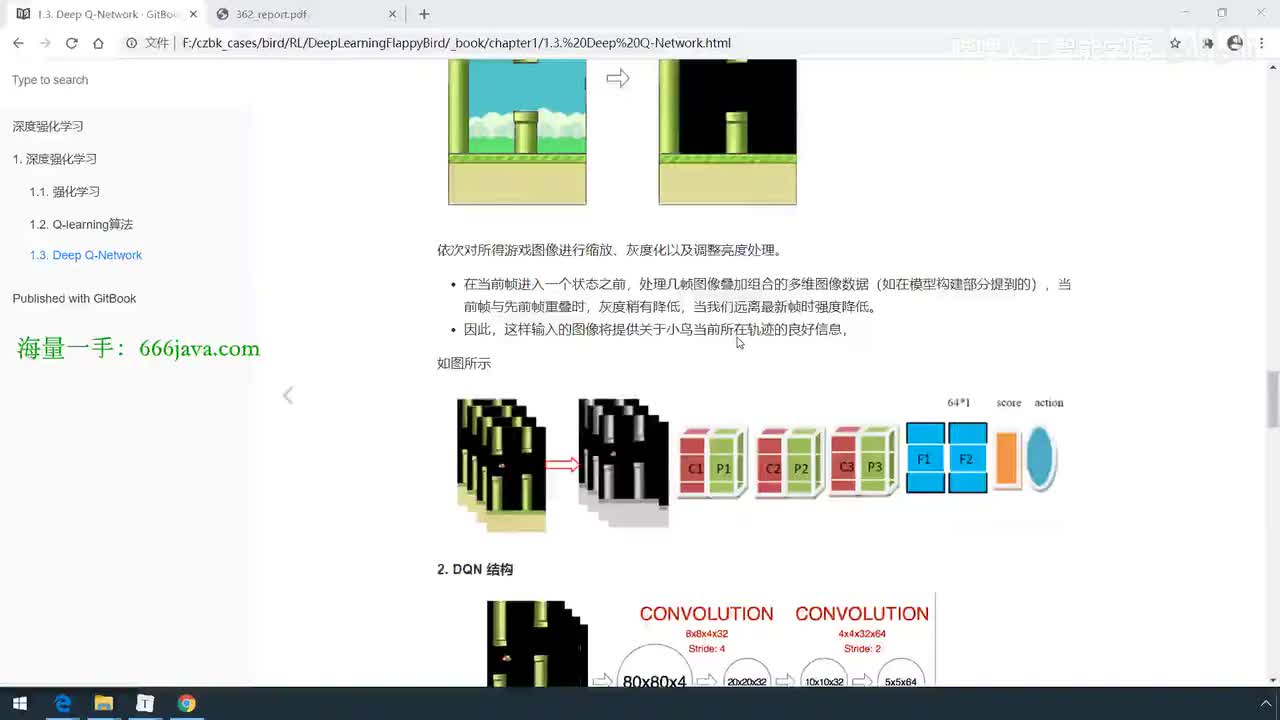
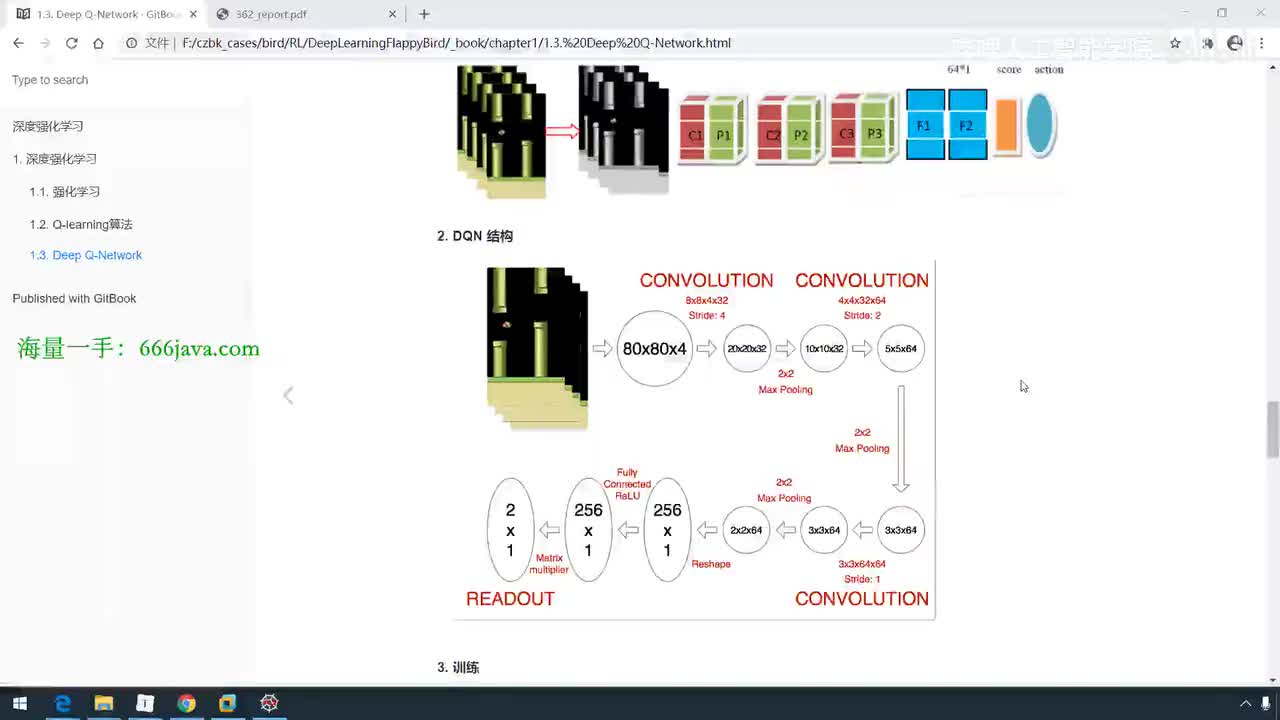
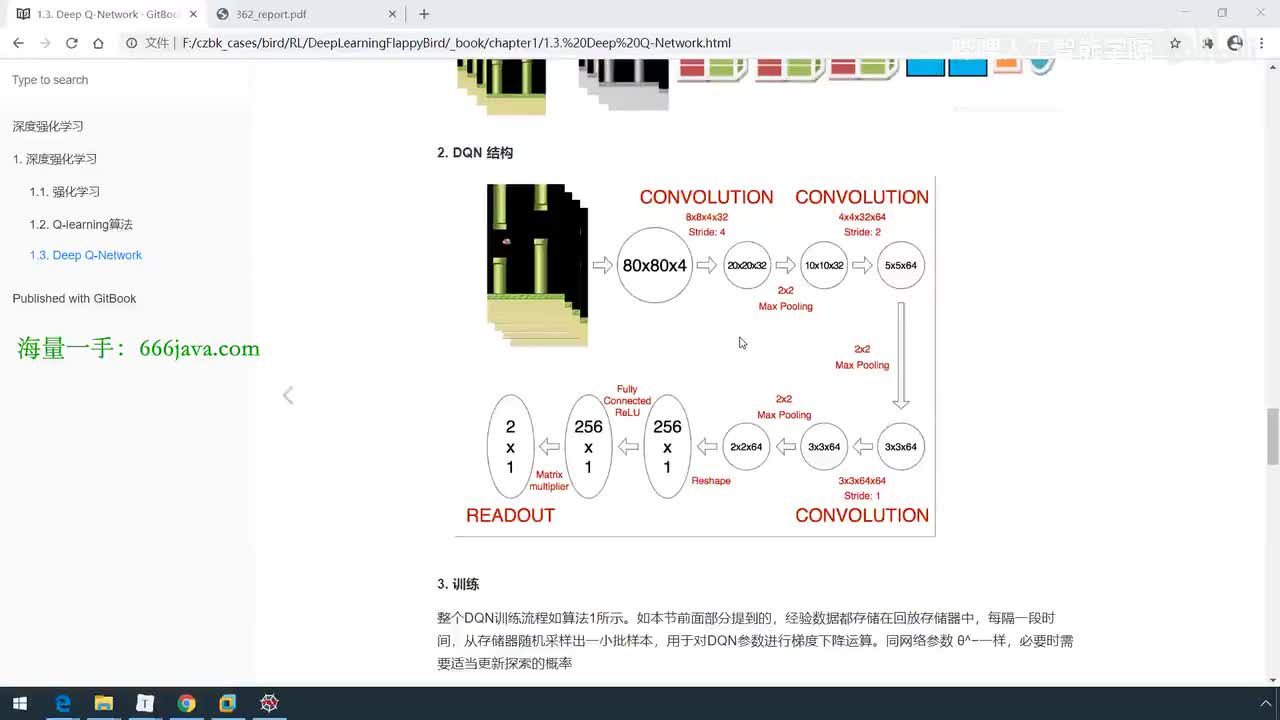
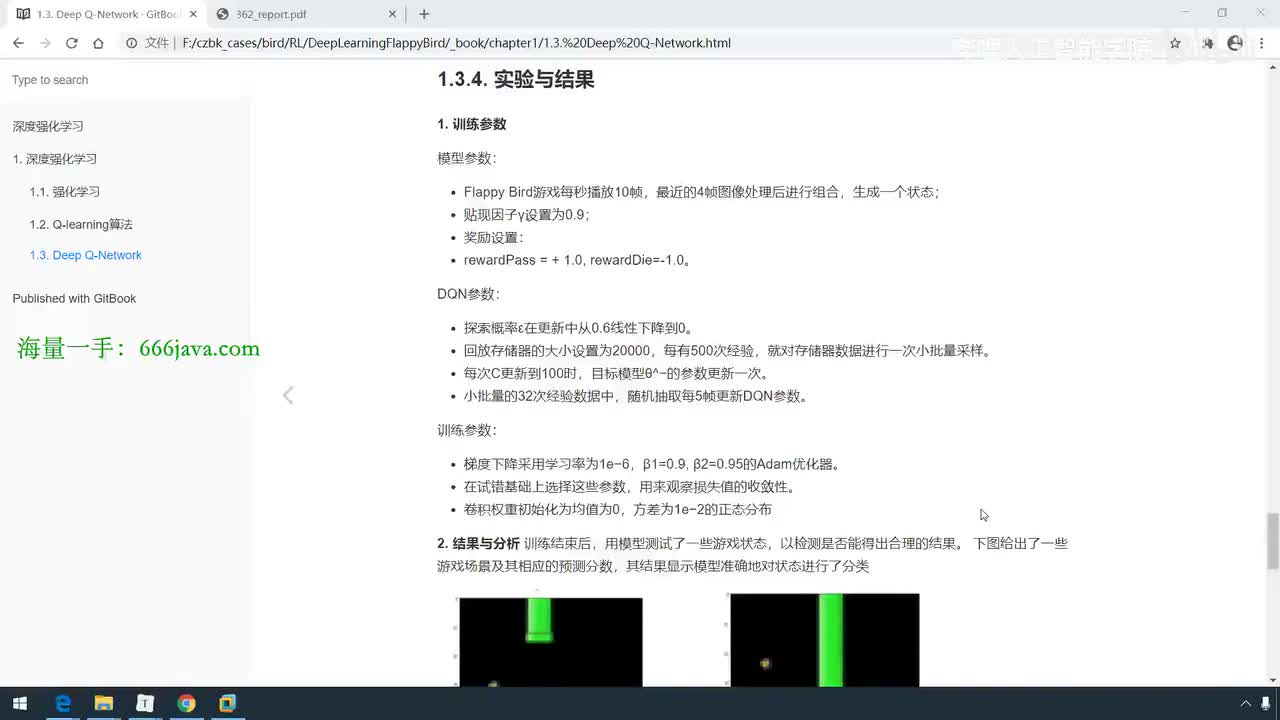
UP主: 封面: 简介:up还给大家整理了60G人工智能入门学习资.源,一并发送!!!一、AI必读经典电子书(西瓜书、花书、鱼书等)二、CVPR2024+2025论文库、视觉方向顶会论文仓库(可论文指导、S...
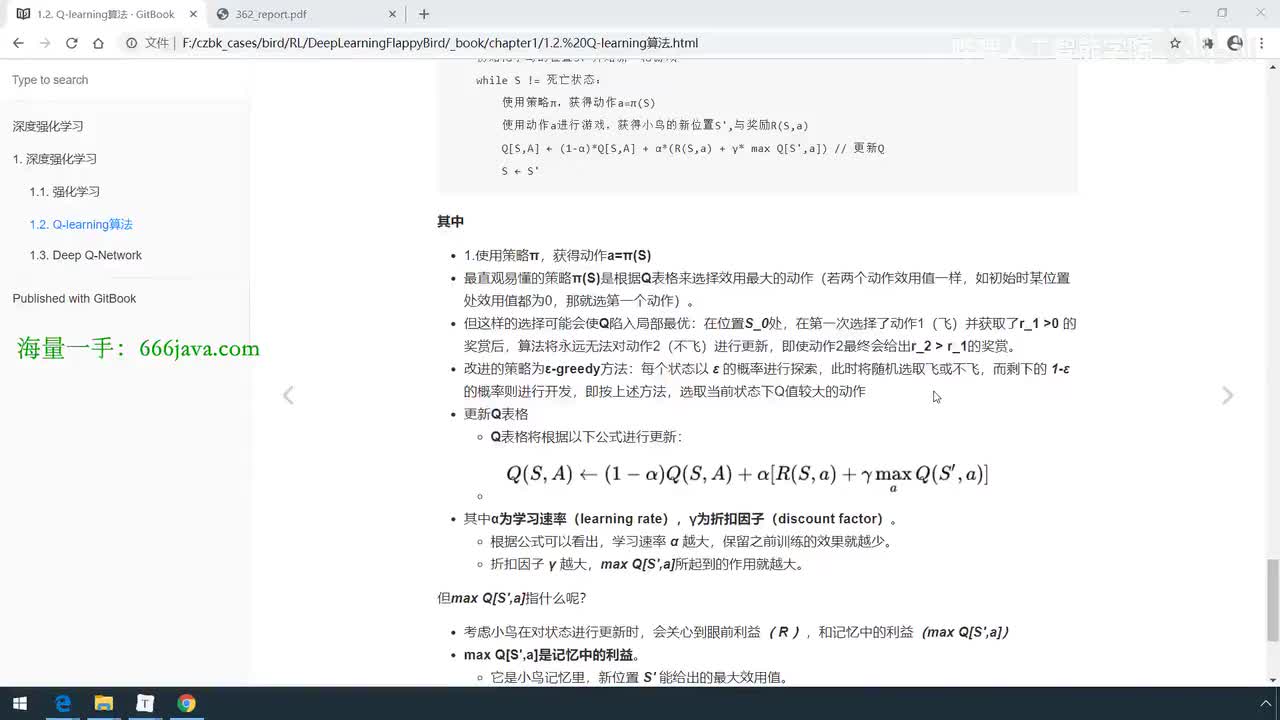
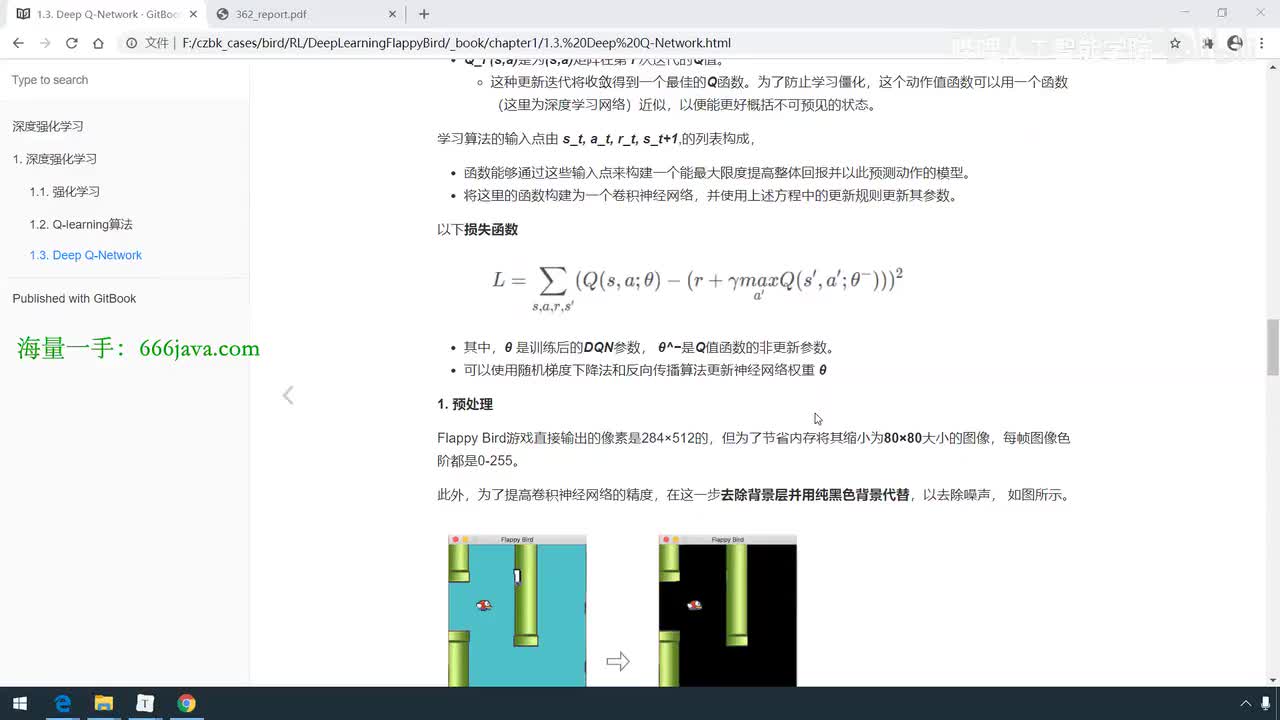
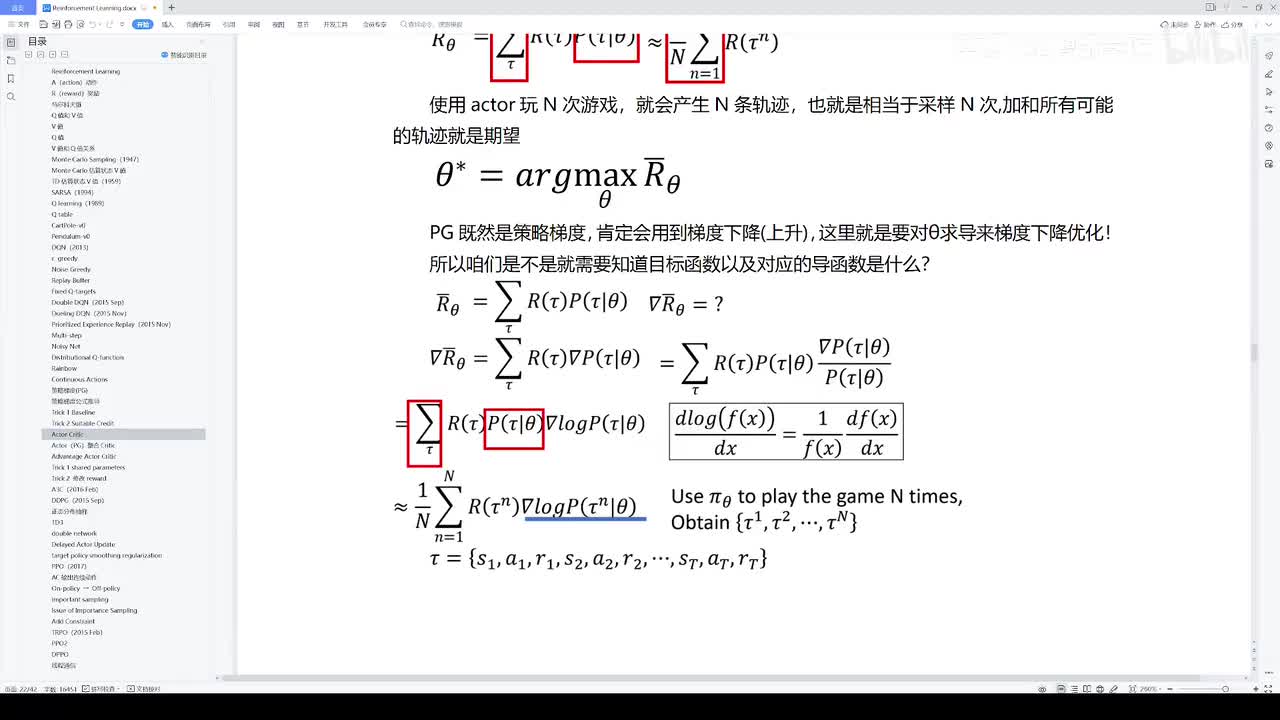
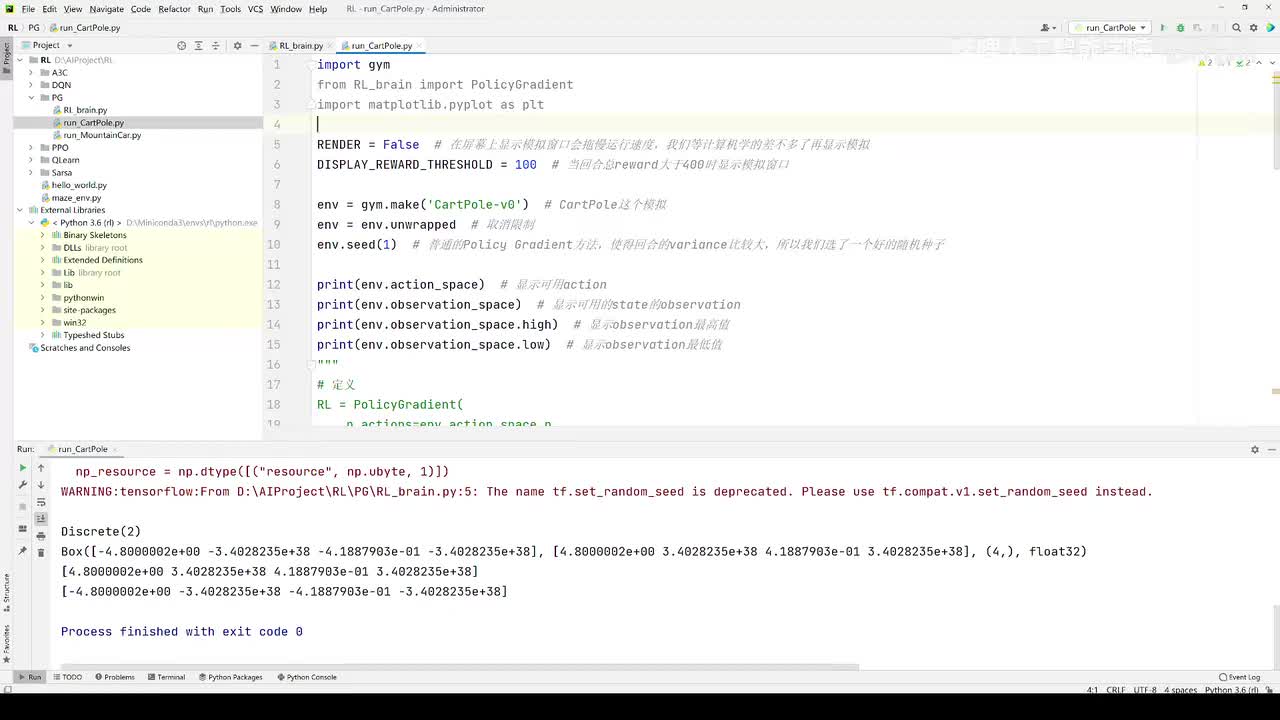
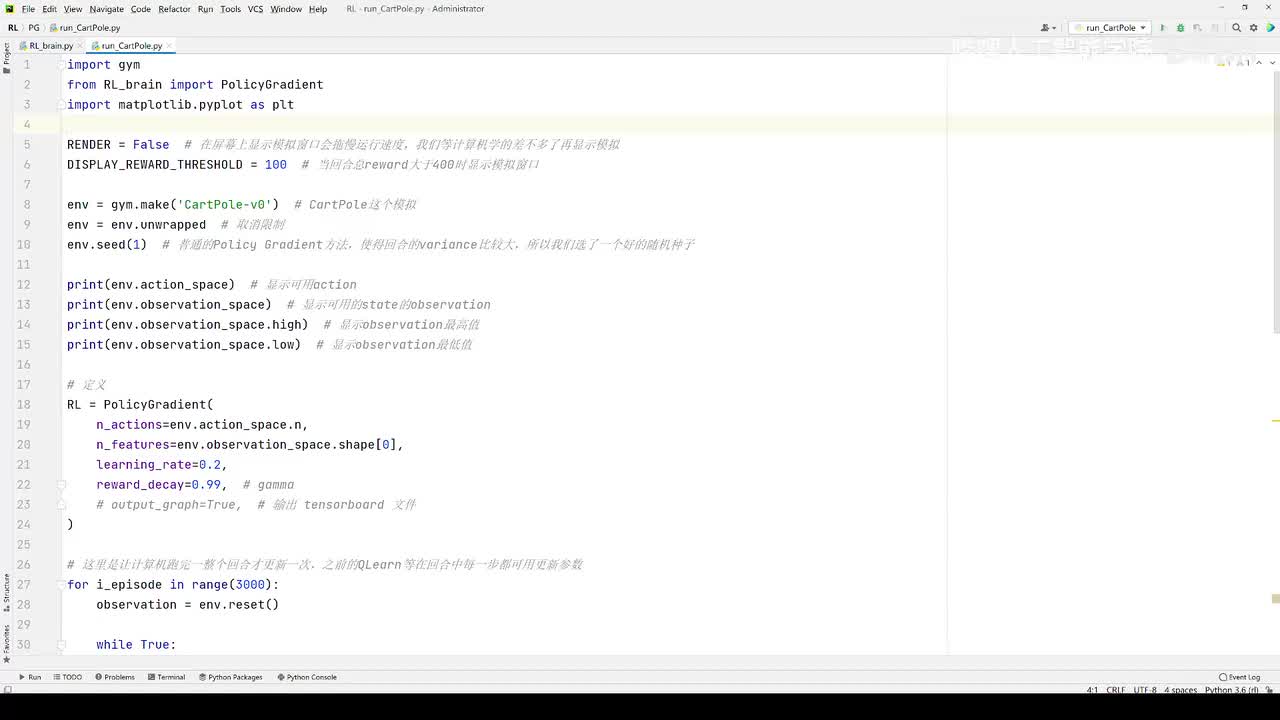
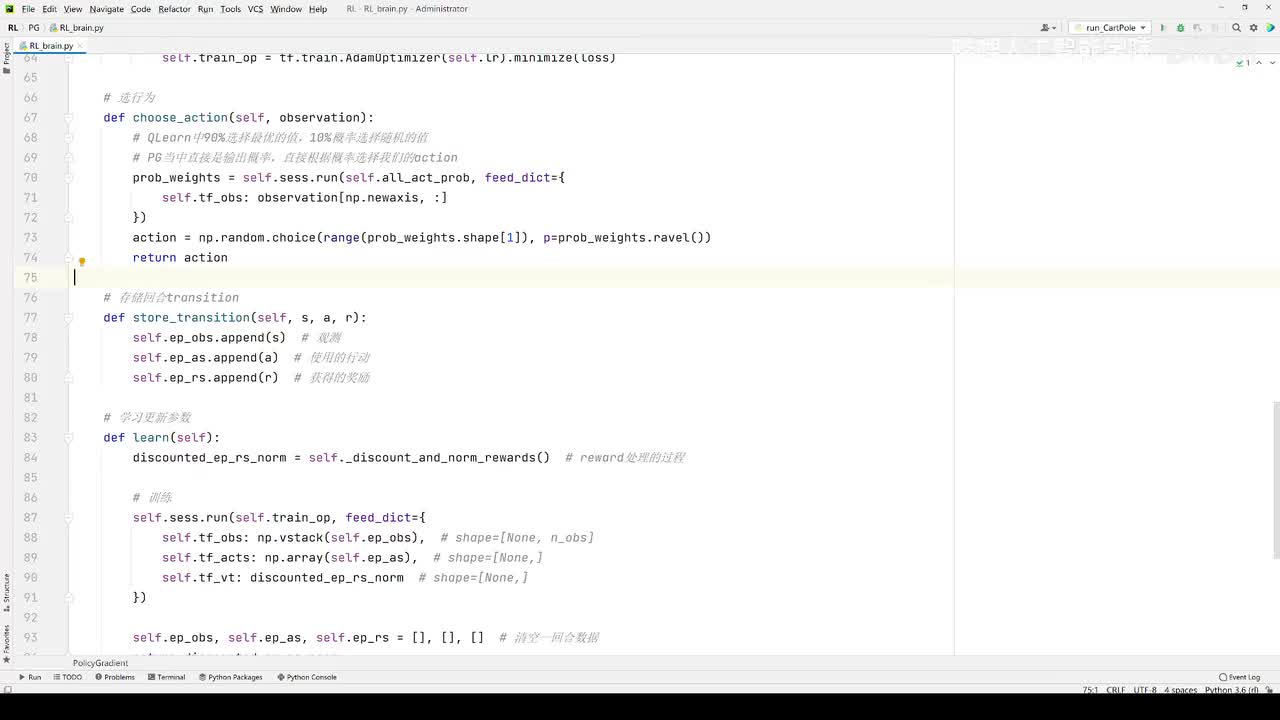
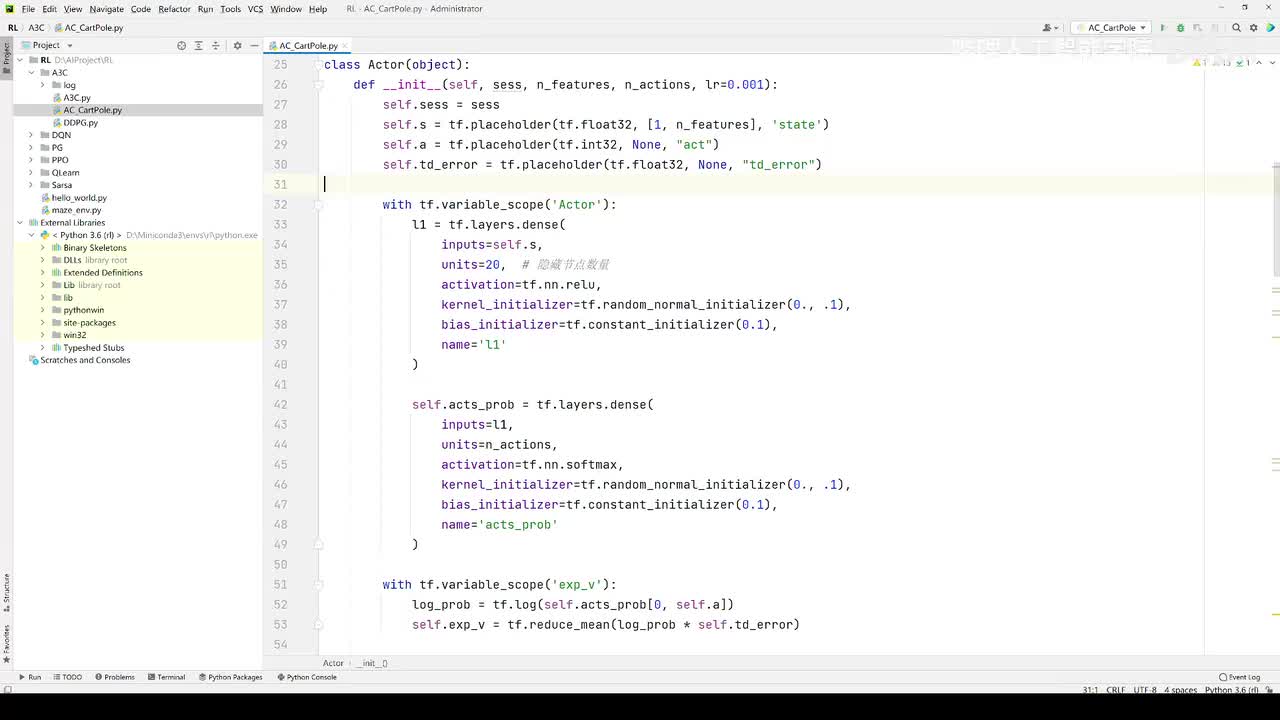
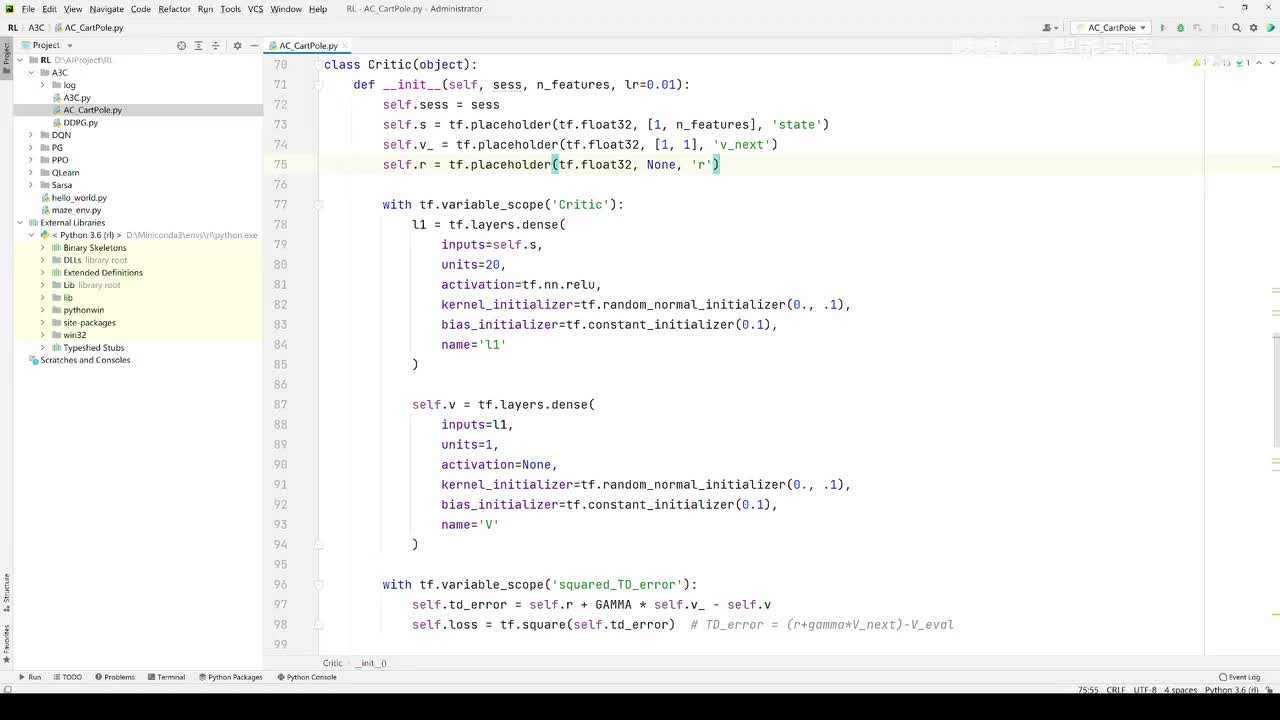
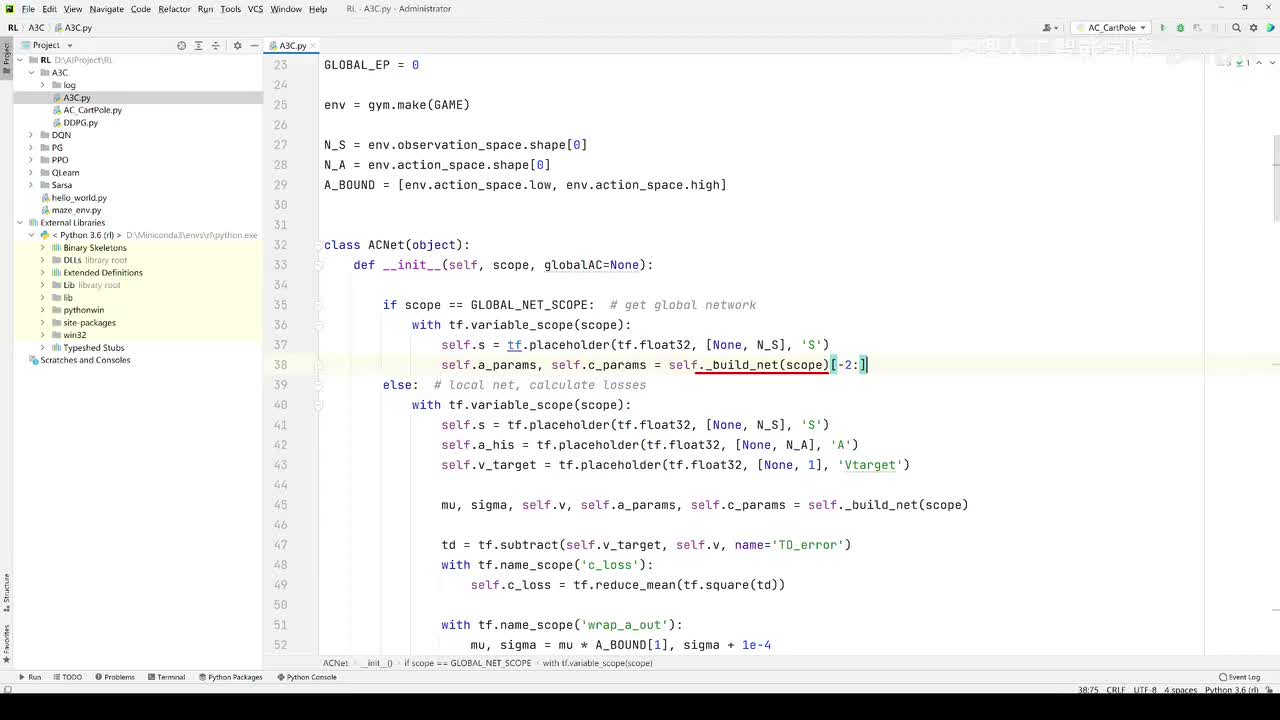
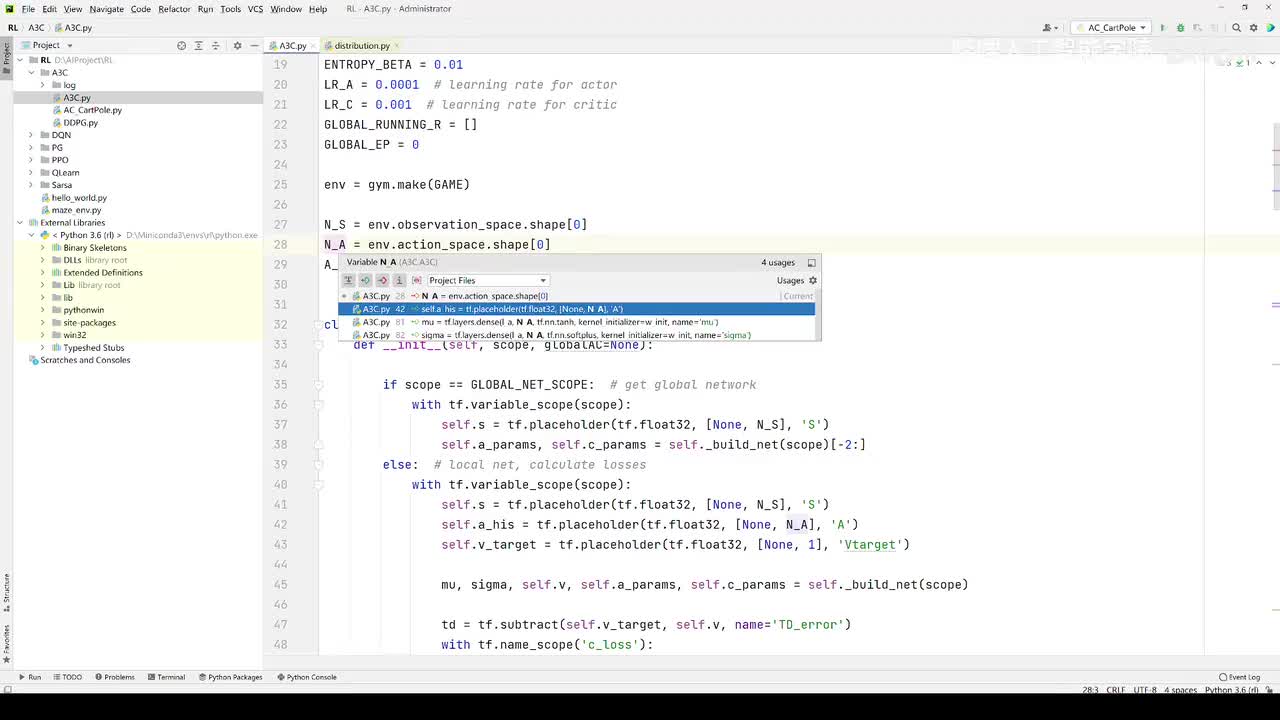
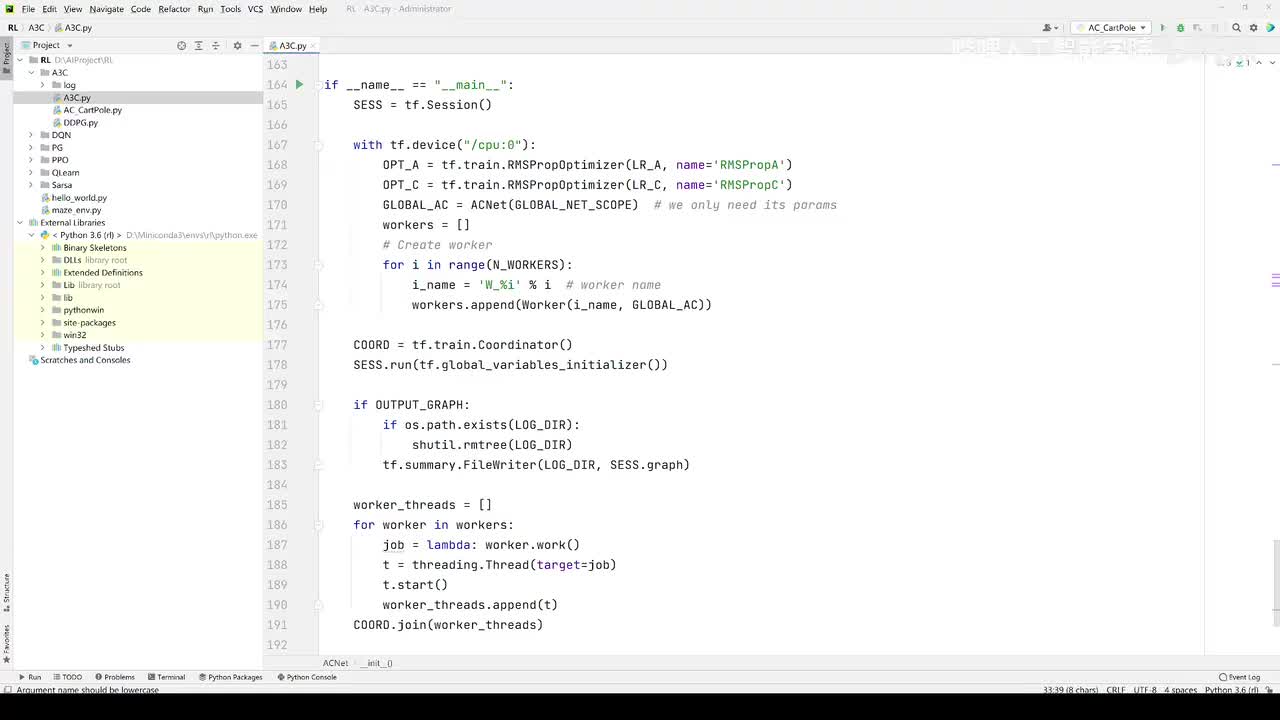
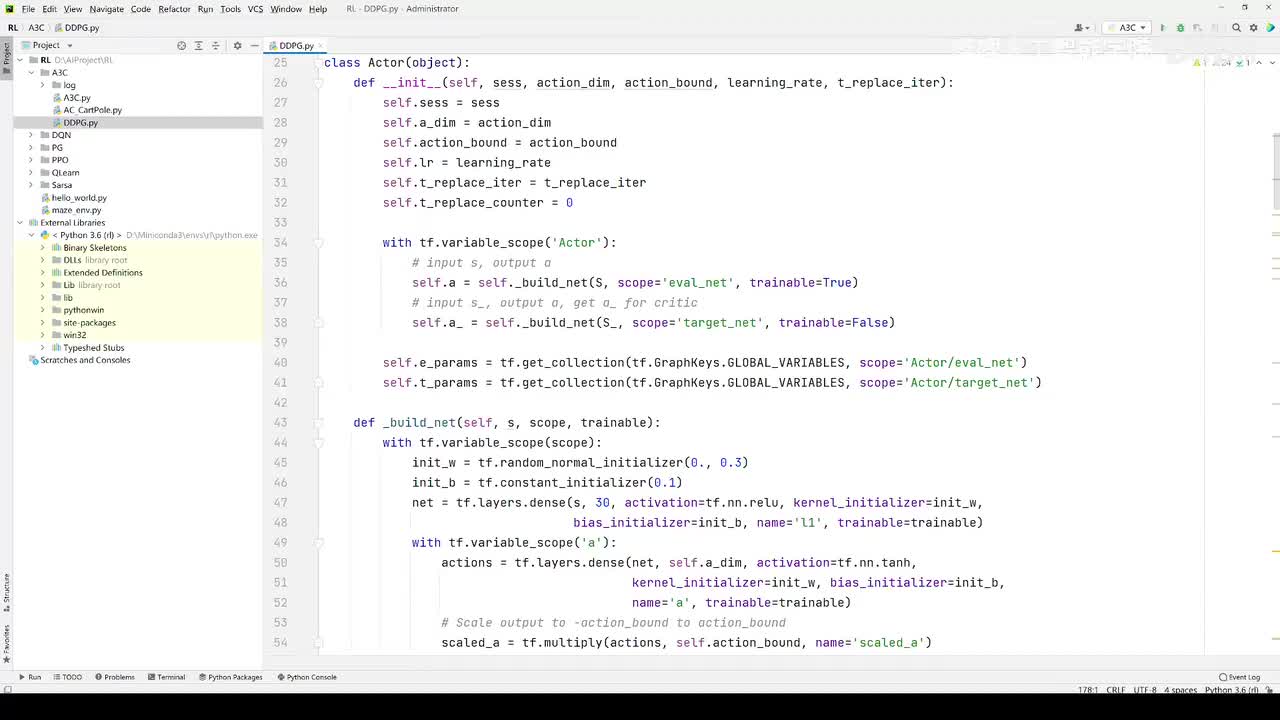
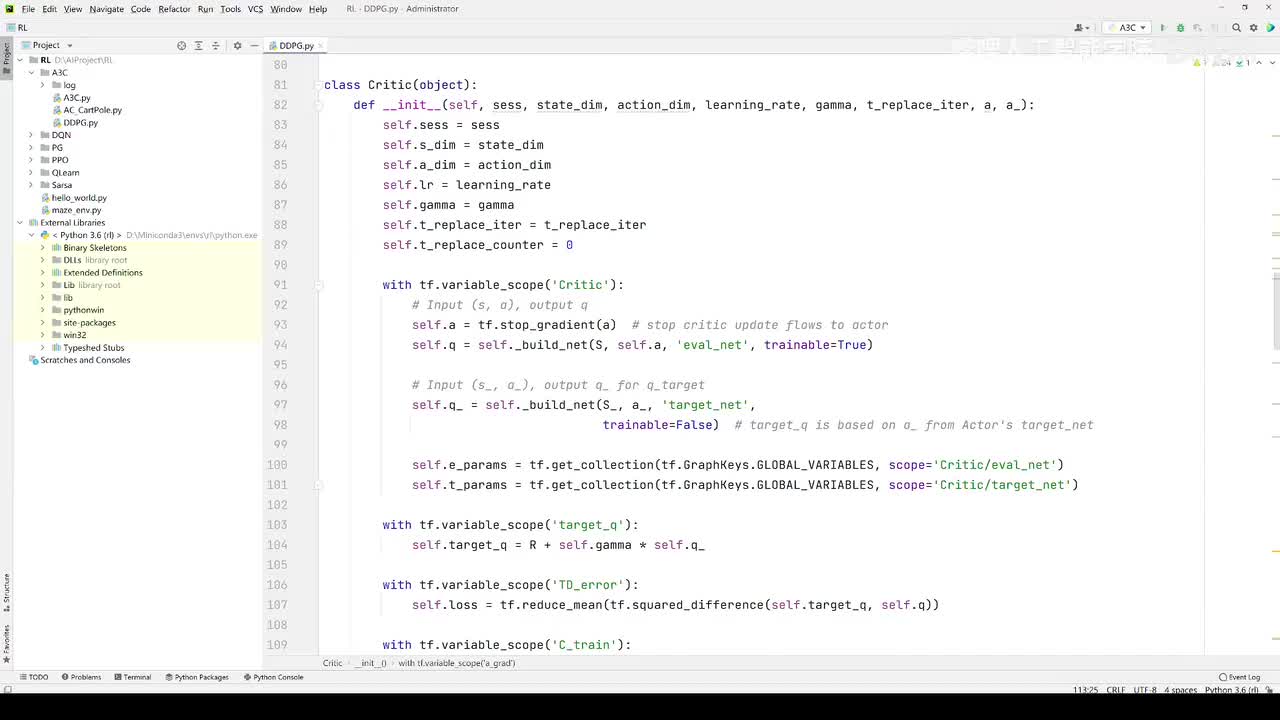
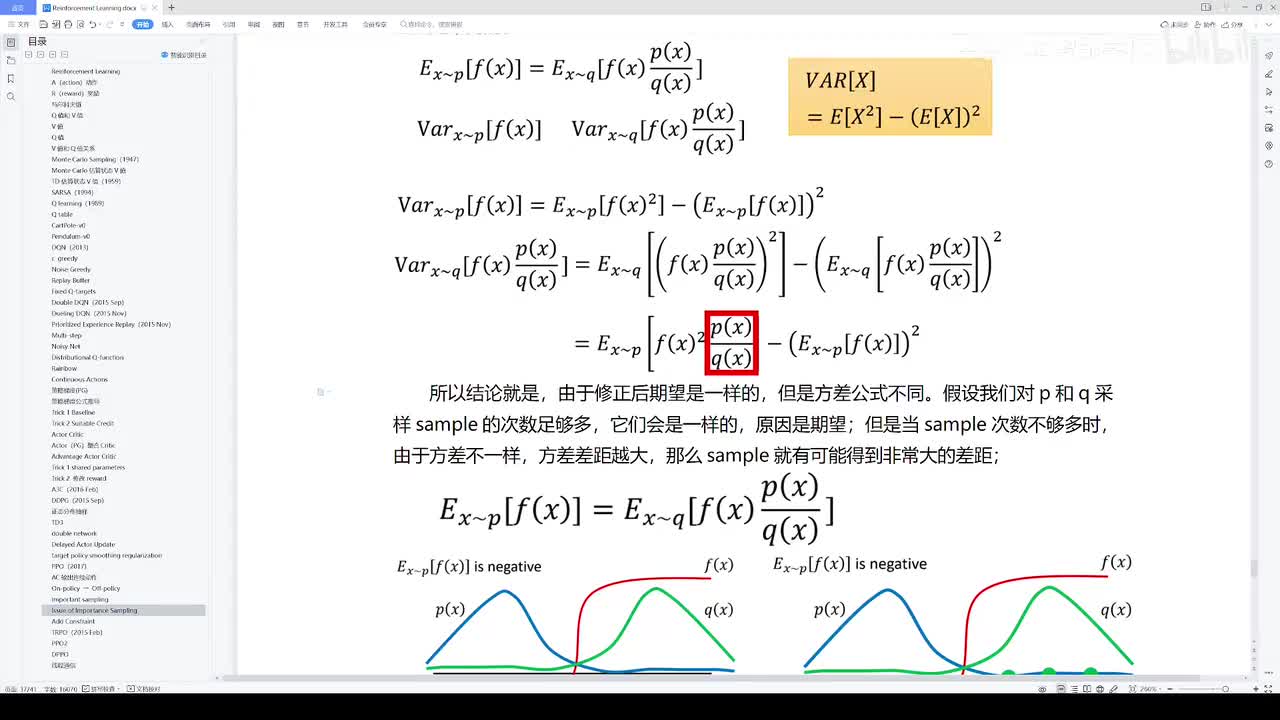
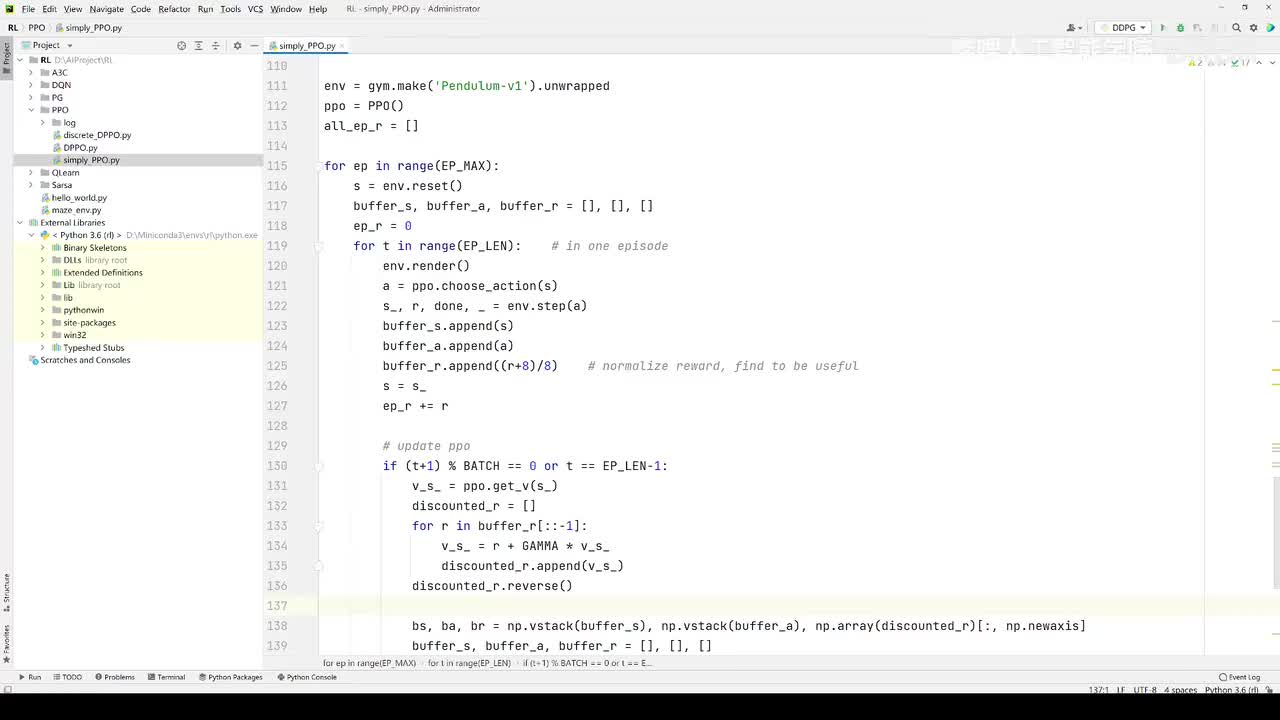
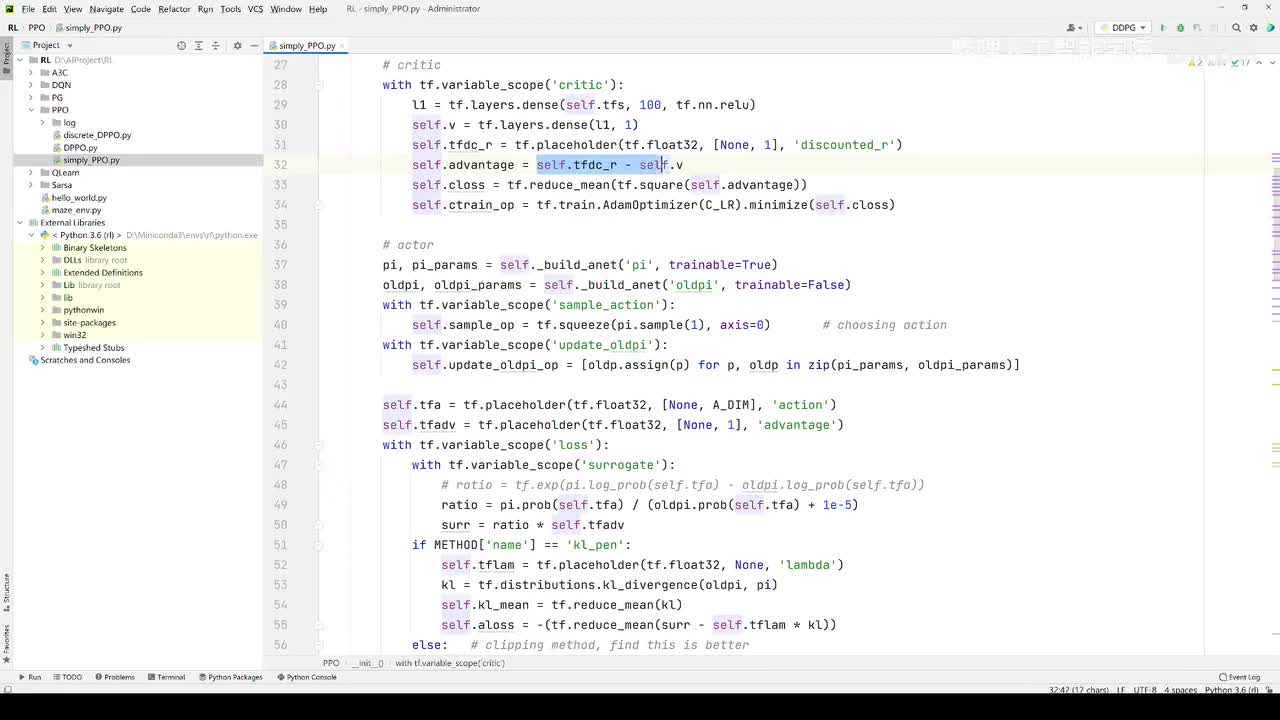
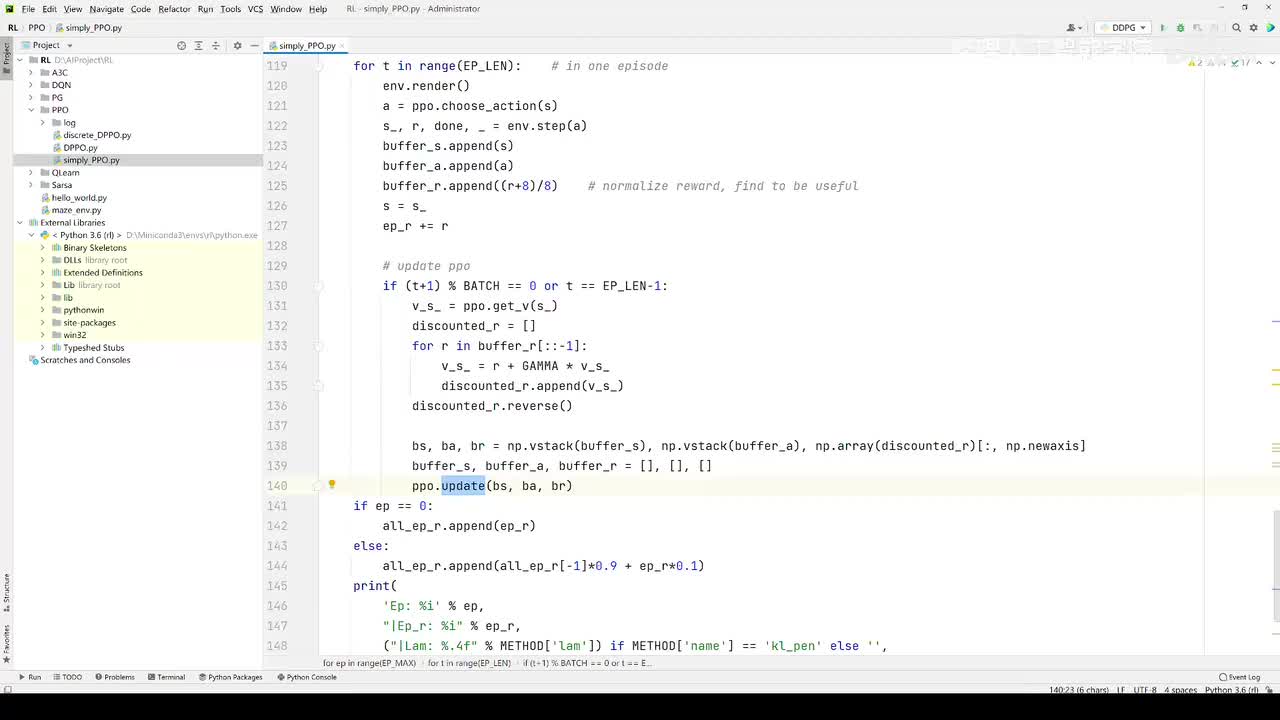
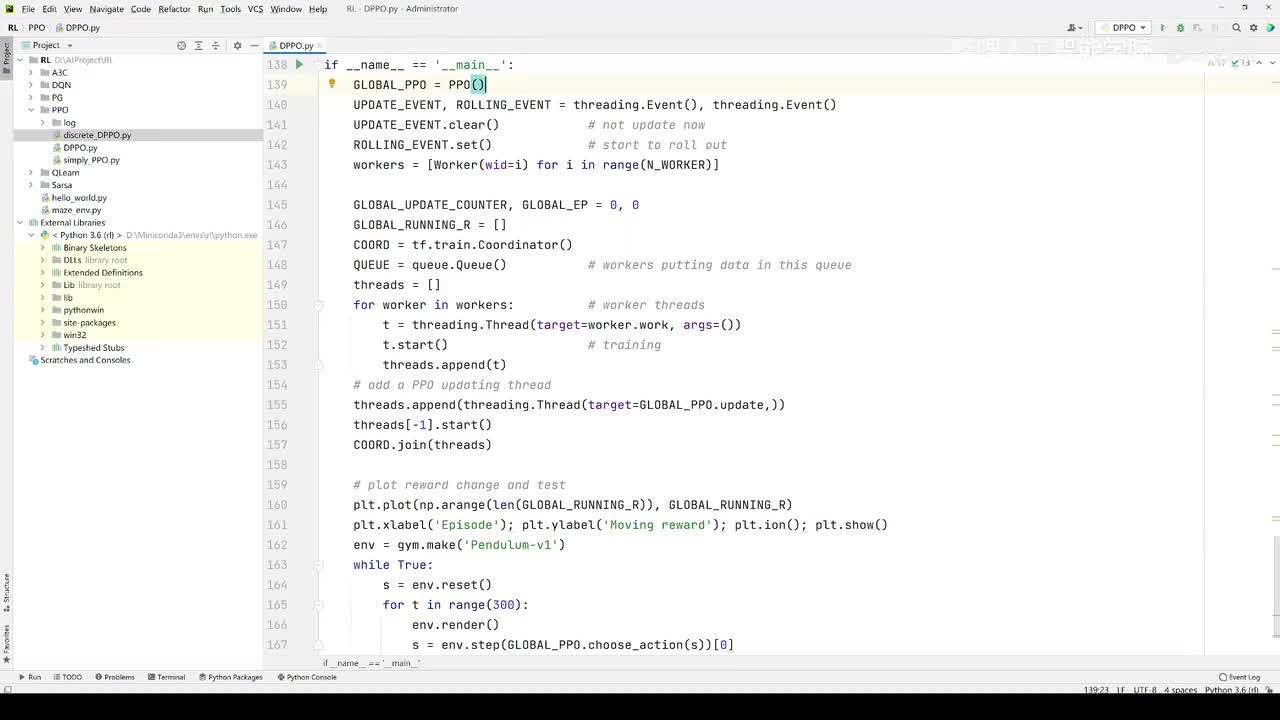
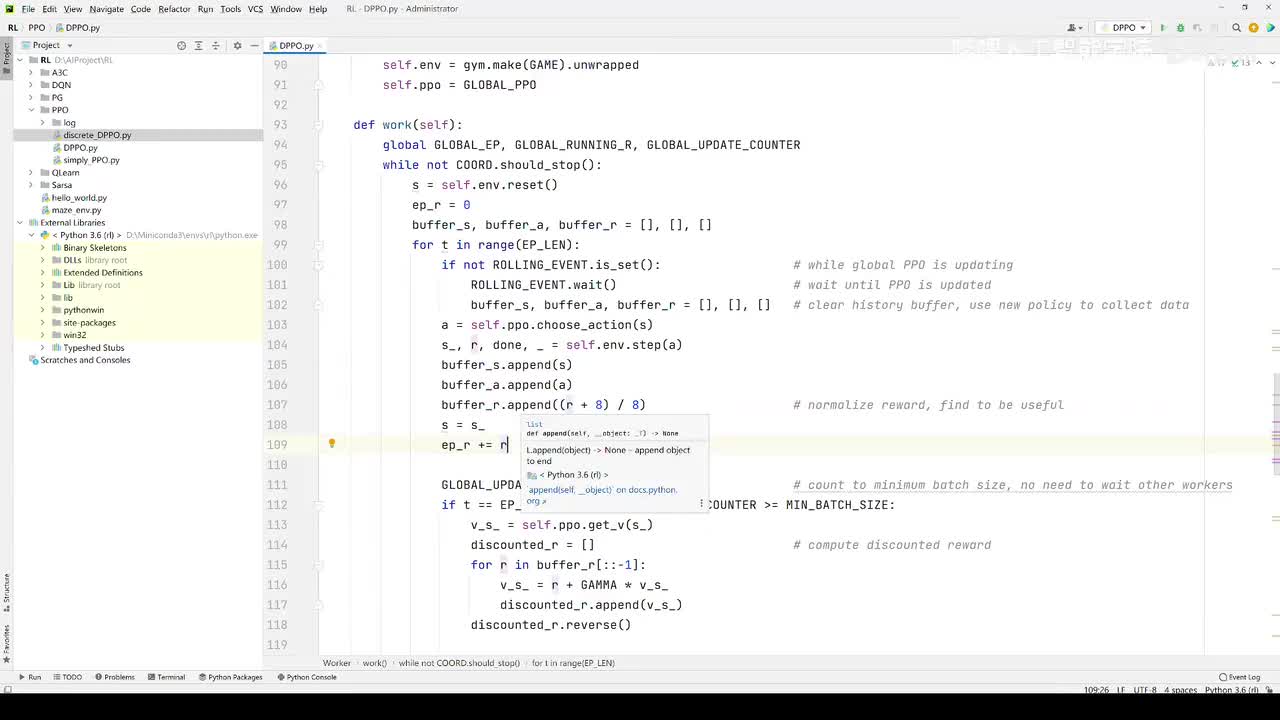
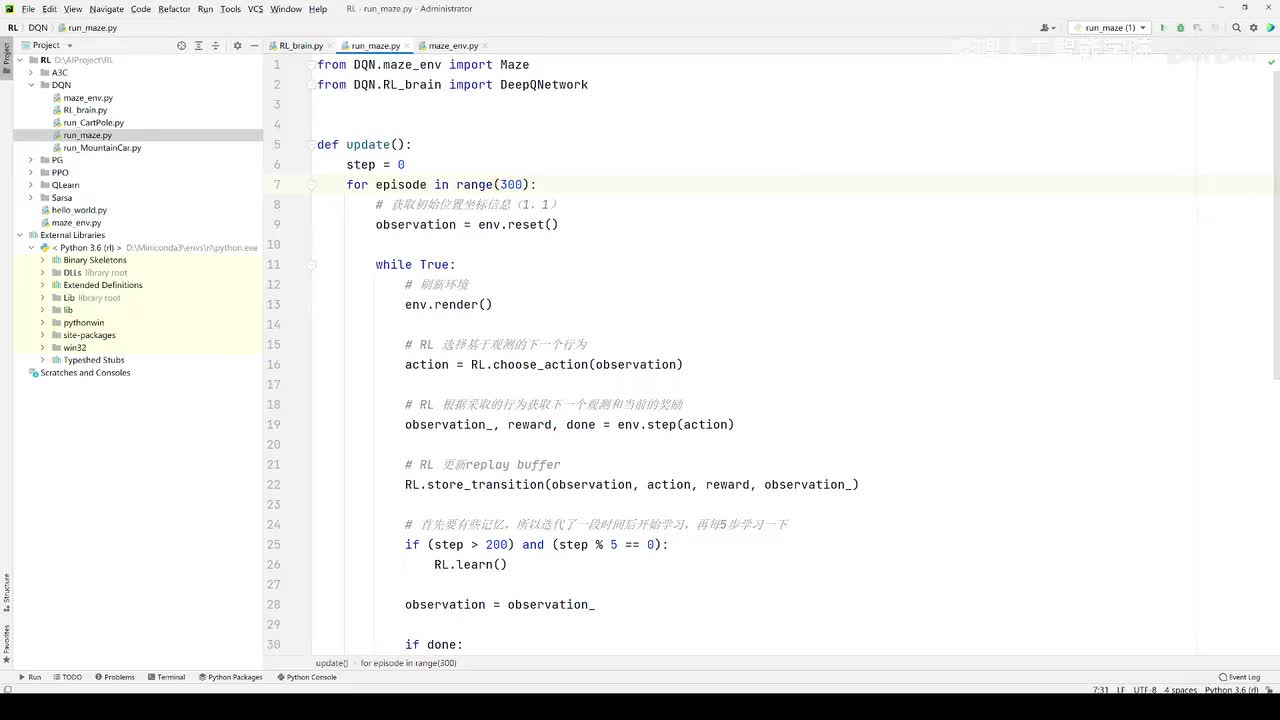
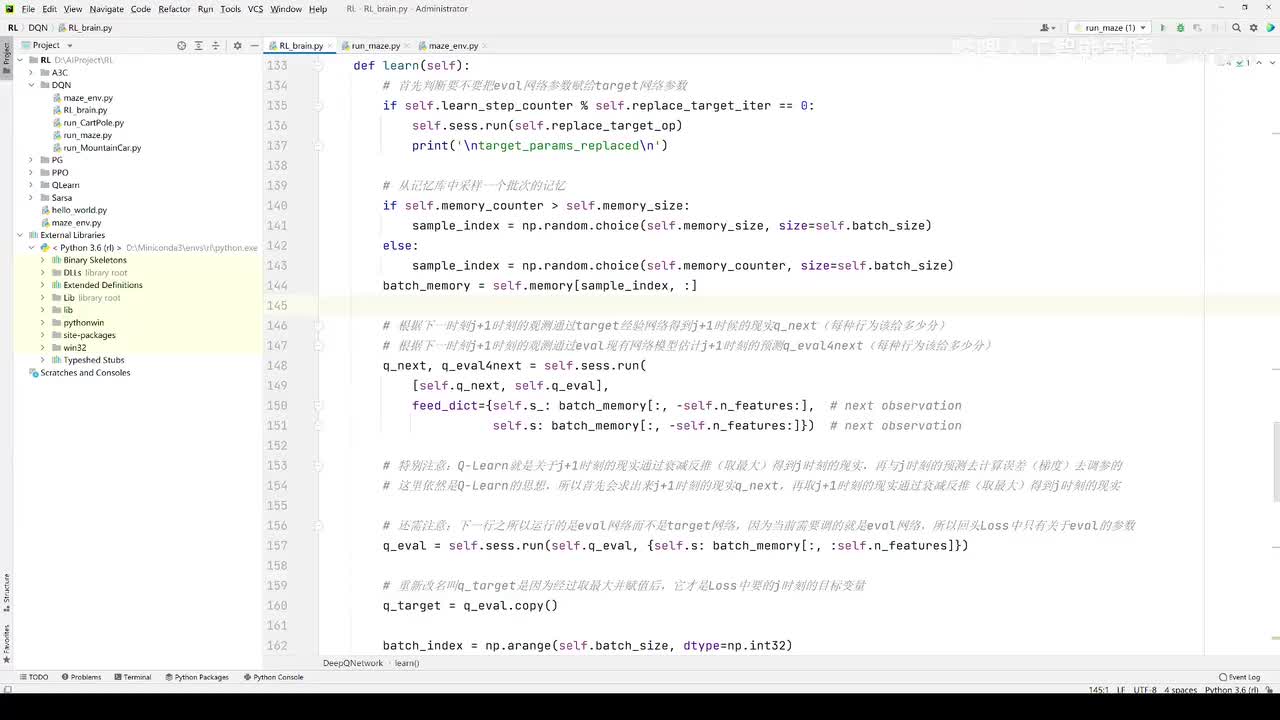
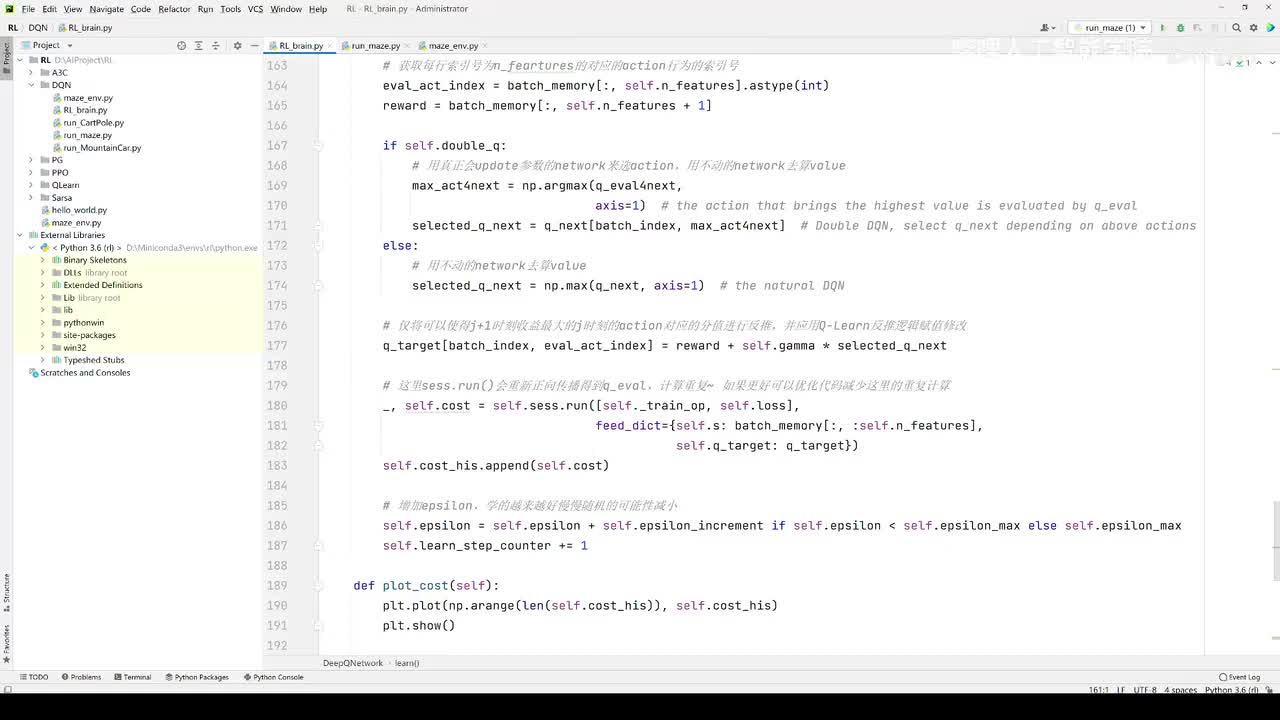
视频选集 【2025版】1-深度强化学习基本概念 【2025版】2-深度强化学习基础:价值学习 【2025版】3-深度强化学习基础:策略学习 【2025版】4-深度强化学习基础:Actor-Critic 【2025版】5-深度强化学习基础:AlphaGo 【2025版】6-数学基础:蒙特卡洛+Monte+Carlo 【2025版】7-Sarsa算法_(TD_Learning_1_3) 【2025版】8-Q-Learning算法+(TD+Learning+2_3) 【2025版】9-Multi-Step+TD+Target+(TD+Learning+3_3) 【2025版】10- 经验回放+Experience+Replay+(价值学习高级技巧+1_3) 【2025版】11-Dueling+Network+(价值学习高级技巧+3_3) 【2025版】12-多智能体强化学习(1_2):基本概念++Multi-Agent+Reinforcement+Learning 【2025版】13-多智能体强化学习(2_2):三种架构++Multi-Agent+Reinforcement+Learning 【2025版】14-策略梯度中的Baseline+(1_4) 【2025版】15-REINFORCE+with+Baseline+(策略梯度中的Baseline+2_4) 【2025版】16- A2C+方法+(策略梯度中的Baseline+3_4) 【2025版】17-REINFORCE与A2C的异同+(策略梯度中的Baseline+4_4) 【2025版】18-离散控制与连续控制+(连续控制+1_3) 【2025版】19-确定策略梯度+Deterministic+Policy+Gradient,+DPG+(连续控制+2_3) 【2025版】20-随机策略做连续控制+(连续控制+3_3) 【2025版】21-新版强化学习 01.深度强化学习简介0 【2025版】22-强化学习介绍 【2025版】23-强化学习方法 【2025版】24-强化学习特点 【2025版】25-强化学习基本过程 【2025版】26-强化学习步骤 【2025版】27-贝尔曼方程 【2025版】28-Q函数 【2025版】29-Q-learning算法 【2025版】30-Q-learning伪代码 【2025版】31-Q值更新 【2025版】32-Q值计算 【2025版】33-Flappy-Bird游戏说明 【2025版】34-状态与动作选择 【2025版】35-Q-table 【2025版】36-初始策略 【2025版】37-Q值更新策略 【2025版】38-Deep-Q-Network介绍 【2025版】39-问题分析 【2025版】40-实现方法 【2025版】41-构建模型 【2025版】42-Q学习损失函数 【2025版】43-论文解读和图像预处理 【2025版】44-Q-learning算法-CNN输入 【2025版】45-DQN结构 【2025版】46-DQN代码分析 【2025版】47-DQN训练流程 【2025版】48-DQN训练代码分析 【2025版】49-DQN训练演示 【2025版】50.-DQN实验分析 【2025版】51-Policy Gradient 策略梯度PG_对比基于值和基于策略网络的区别 【2025版】52-策略梯度PG_明确目标函数和导函数 【2025版】53-策略梯度PG_简化导函数的公式推导 【2025版】54-策略梯度PG_总结整体流程_对比交叉熵损失函数求导 【2025版】55-策略梯度PG_讲解CartPole环境 【2025版】56-代码实战_策略梯度PG和CartPole交互 【2025版】57-代码实战_策略梯度PG网络构建 【2025版】58-代码实战_策略梯度PG选择行为和参数训练 【2025版】59-策略梯度PG_对TotalReward进行均值归一化 【2025版】60-策略梯度PG_同一个回合中不同的action回溯不同的TotalReward_代码实战 【2025版】61-ActorCritic原理_把PG和QLearning结合起来 【2025版】62-AdvantageActorCritic_共享参数和修改reward技巧 【2025版】63-代码实战_ActorCritic与环境交互 【2025版】64-代码实战_Actor网络构建及训练 【2025版】65-代码实战_详解Critic网络构建及训练 【2025版】66-A3C架构和训练流程 【2025版】67-Pendulum环境_根据网络预测的μ和σ得到连续型的action值 【2025版】68-代码实战_A3C_讲解Coordinator调度多线程运算 【2025版】69-代码实战_A3C_定义Worker计算loss的逻辑_针对连续型的action提高actor探索性 【2025版】70-代码实战_A3C_增加actor探索性用到熵_定义worker正太分布抽样和求梯度的逻辑 【2025版】71-代码实战_A3C_定义AC网络结构_定义worker拉取参数和更新全局网络参数的逻辑 【2025版】72-代码实战_A3C_结合流程图分三点总结前面讲的代码 【2025版】73-代码实战_A3C_讲解线程中worker和环境交互 【2025版】74-代码实战_A3C_讲解线程中worker和GlobalNet交互_代码运行效果展示 【2025版】75-ODDPG、PP、DPPO算法 -DDPG解决DQN不能输出连续型动作的问题_DDPG如何训练Actor和Critic 【2025版】76-代码实战_DDPG_构建Actor和Critic四个网络_定义Critic求loss和求梯度的逻辑 【2025版】77-代码实战_DDPG_Critic网络构建_Actor网络链式求导 【2025版】78-代码实战_DDPG_与环境之间的互动_AC训练调整参数_效果展示 【2025版】79-TD3_使用DoubleNetwork优化DDPG 【2025版】80-PPO_强调AC如何输出连续型动作_区分On-Policy与Off-Policy 【2025版】81-PPO_通过重要性采样使得PPO可以做Off-Policy学习 【2025版】82-PPO_重要性采样的问题_期望矫正但是方差还是不同带来的问题 【2025版】83-PPO_PPO1、TRPO、PPO2三种不同的方式解决两个分布不同的问题 【2025版】84-代码实战_PPO与环境整体交互_Actor与Critic网络构建 【2025版】85-代码实战_定义PPO1和PPO2不同版本Actor的Loss计算逻辑 【2025版】86-代码实战_剖析PPO代码中如何体现Off-Policy的学习方式_效果展示 【2025版】87-DPPO分布式PPO 【2025版】88-代码实战_DPPO_创建一个PPO和多个Worker_创建多线程 【2025版】89-代码实战_DPPO_GlobalPPO和Workers交替执行 【2025版】90-DQN算法思想 【2025版】91-DQN算法具体流程 【2025版】92-ε-greedy_ReplayBuffer_FixedQ-targets 【2025版】93-代码实战DQN_Agent和Env整体交互 【2025版】94-代码实战DQN_构建Q网络 【2025版】95-代码实战DQN_定义损失函数_构建Target网络更新逻辑 【2025版】96-代码实战DQN_训练阶段得到Q网络的预测值和真实值 【2025版】97-代码实战DQN_训练阶段最小化损失_记录loss方便展示_随着learn的越多选择action随机性减小 【2025版】98-DQN会over-estimate的本质原因 【2025版】99-DoubleDQN缓解over-estimate
哔哩人工智能学院的视频 【2025最新版】王树森深度强化学习全套课程(280集)涵盖PPO算法/DQN算法/A3CQ-Learning/SARSA算法等强化学习经典算法!学完即可就业! 【Transformer】最强动画讲解!目前B站最全最详细的Transformer教程,2025最新版!从理论到实战,通俗易懂解释原理,草履虫都学的会! 【Transformer】最强动画讲解!目前B站最全最详细的Transformer教程,2025最新版!通俗易懂解释原理,最适合小白学习的AI入门级教程了!